Converting tabular data to RDF: Load data
LP-ETL allows you to store your data in many ways, so that others may reap the results of your work. You can store files locally using the Files to local component or you can push them to a remote server via the Secure Copy Protocol with the Files to SCP component. You can load data to RDF stores, either using the SPARQL 1.1 Graph Store HTTP Protocol via the Graph Store Protocol component, using SPARQL 1.1 Update via the SPARQL endpoint component, or via the proprietary bulk loader for Virtuoso.
In our example pipeline we export the data to files and to a Virtuoso RDF store.
RDF can be written to files using the RDF to file component.
It can write RDF in many serializations, including formats for triples, such as Turtle, or formats for quads, such as TriG.
Quad-based formats allow you to specify a named graph into which the triples of your data will be wrapped.
Our pipeline produces RDF dumps in the TriG format, which offers a compact and readable way to represent RDF quads.
For each dump we specify a named graph IRI.
By convention, we use the IRI of the skos:ConceptScheme instance for the LAU code list (i.e. https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016), and the IRI of the qb:DataSet instance (i.e., https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016/statistics) for the associated statistical data cube.
In order to save space we compress the RDF dumps via the Stream compression component. Text-based RDF serializations contain redundant substrings, such as namespaces shared between absolute IRIs, so that compression can significantly decrease the size of RDF dumps. The effect of compression is particularly apparent in line-based formats, such as N-Triples or N-Quads, which lack shorthand notations for RDF, such as namespaced compact IRIs. Nevertheless, space savings can be achieved also in compact RDF formats. For example, our statistical data cube in TriG has 131 MB uncompressed. Compressed via gzip it shrinks to 2.3 MB. Compression by bzip2 decreases the size even further, to 1.3 MB, although this method of compression takes longer as it is more computationally demanding. As you can see, we can achieve a two orders of magnitude decrease in file size when using compression.
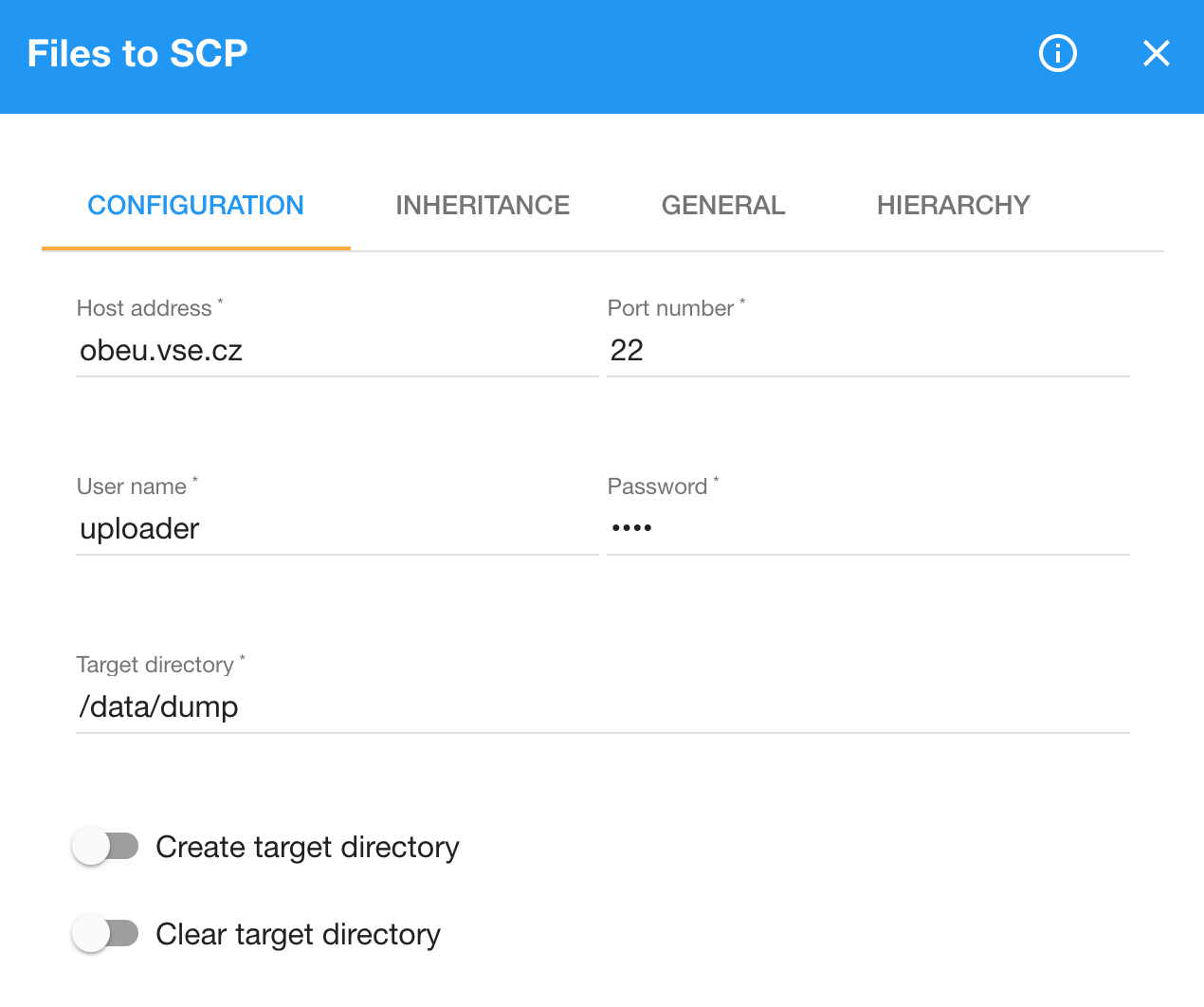
We save the compressed files to a remote server using the Files to SCP component. This component asks you to provide the host address of your server, access credentials, and the target directory. If your server accepts SCP connections on a different port than the default 22, you must fill the port number into the component. The supplied access credentials consist of a user name and a password of a user that is authorized to write files into the target directory. On your server, you can create a dedicated user with permissions restricted to a part of the file system that stores the uploaded data dumps. Files to SCP also allows you to configure that the target directory should be created unless it already exists. Moreover, you can have the component clear the target directory before loading your files. For example, you can use this feature to delete obsolete dumps from prior executions of the pipeline. If you want to publish the data, it is a good idea to push it to a directory that is exposed via an HTTP server. That way, the data will be automatically made available for download from the server.
To load the data into an RDF store we use the Virtuoso component.
This is a peculiar component, since it accepts its input indirectly.
Instead of providing it with data via an input edge, it loads the data from a specified directory on the server where the Virtuoso RDF store runs.
Since the component depends on RDF dumps being loaded by Files to SCP, it is connected to it via the Run before edge.
To create this edge, click on the Files to SCP component that must complete before the Virtuoso component can load the data, select the Run before button, and drag it to the Virtuoso component.
Note that the directory from which Virtuoso loads data must be present in the DirsAllowed section of the virtuoso.ini file.
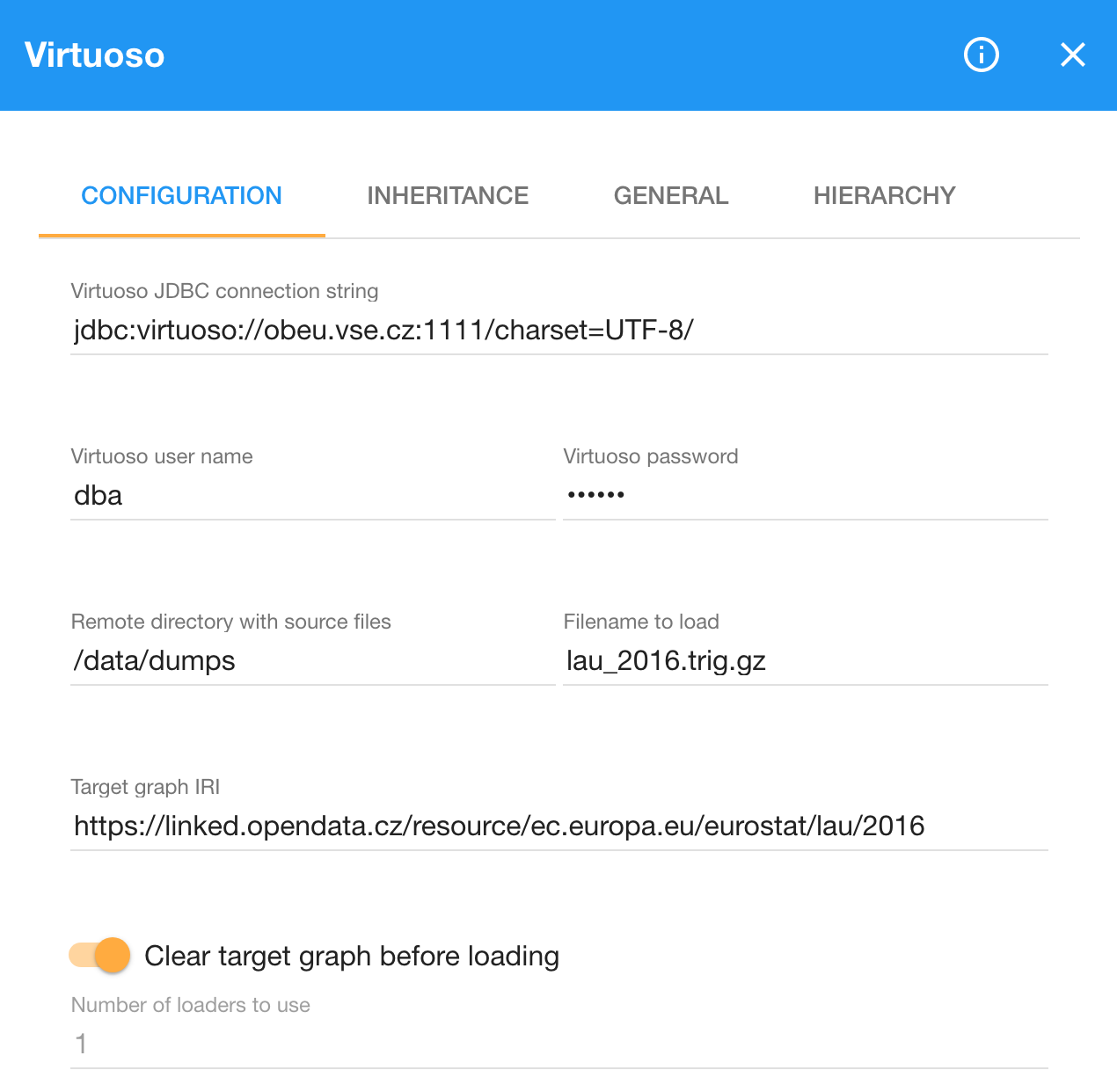
The component connects to Virtuoso via JDBC, so you need to provide it with the JDBC connection string, which typically has the format of jdbc:virtuoso://{host name}:1111/charset=UTF-8/.
In order to authorize LP-ETL to push data to Virtuoso, you must give it the Virtuoso user name and password.
To locate the RDF dump to import to Virtuoso, you enter its directory and file name to the component's configuration.
The component can load multiple files that match a given file mask, such as *.ttl to load all Turtle files in the directory with the .ttl suffix.
To load RDF triples into a particular named graph, specify it by using the Target graph IRI. If you are updating an existing dataset, you can switch on the option to clear the target graph before loading, so that the existing old data is removed. When you load data in a quad-based format, such as TriG, it explicitly specifies its named graph, so that the Target graph IRI will not be used for the loaded data. It will, however, be used to clear previous data present in the named graph.
To speed up loading large datasets, you can increase the number of loaders to use, so that multiple loaders can run in parallel. To get the best performance, the number of loaders should correspond to the number of CPU cores available on the server running the Virtuoso. The use of the Virtuoso loader is recommended for larger datasets that contain millions of RDF triples, since the other methods for loading data to RDF stores are better suited for smaller datasets.
Here you can find the example pipeline with the loaders included. The pipeline is exported without the credentials required by loaders. You can share a pipeline with no private configuration by using the option to download it without credentials. This is useful when you want to share a pipeline publicly. Since loaders without the credentials do not work, they are disabled in the example pipeline. You can toggle components between the disabled and the enabled state via their button with the power symbol. Moreover, there is a special mass command that disables or enables all loaders in a pipeline. You can find it by clicking the cogwheel icon in the top right corner of the pipeline view. When components are disabled, their execution is skipped and any following components receive empty input.
