Converting tabular data to RDF: Describe semantics
-
open_withSample RDF input
@prefix : <http://example.com/> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . [ :AREA "1056740000"^^xsd:decimal ; :CHANGE false ; :LAU1_NAT_CODE "146" ; :LAU2_NAT_CODE "005" ; :NAME_1 "Alajärvi"@fi ; :NUTS_3 "FI194" ; :POP 10006 ; :sheet_name "FI" ] . [ :AREA "630200000"^^xsd:decimal ; :CHANGE false ; :LAU1_NAT_CODE "041" ; :LAU2_NAT_CODE "050" ; :NAME_1 "Eura"@fi ; :NUTS_3 "FI196" ; :POP 12128 ; :sheet_name "FI" ] . [ :AREA "495420000"^^xsd:decimal ; :CHANGE false ; :LAU1_NAT_CODE "131" ; :LAU2_NAT_CODE "592" ; :NAME_1 "Petäjävesi"@fi ; :NUTS_3 "FI193" ; :POP 4008 ; :sheet_name "FI" ] .
At this point we have reasonably clean RDF data.
However, the data is described in terms of custom properties, such as :POP or :NUTS3_10.
These properties do not give away much of their meaning, making it difficult to comprehend the data.
In order to improve the usability of the data, we therefore map these custom properties to terms from standard RDF vocabularies.
The dataset is actually made up of two parts.
The first part is a code list of the local administrative units.
Code lists, as well as other controlled vocabularies, can be described using the terms of the Simple Knowledge Organization System (SKOS).
The second part consists of statistical measures about the administrative units.
Specifically, there are population counts and areas in square meters.
Statistical data of this kind can be described by the Data Cube Vocabulary (QB).
Both SKOS and QB are widely used standards by the World Wide Web Consortium (W3C).
In the following, we will refer to the terms of these standards via compact IRIs that use short prefixes in place of namespace IRIs.
You can look up the namespace IRIs of common prefixes, such as skos: and qb:, by using Prefix.cc.
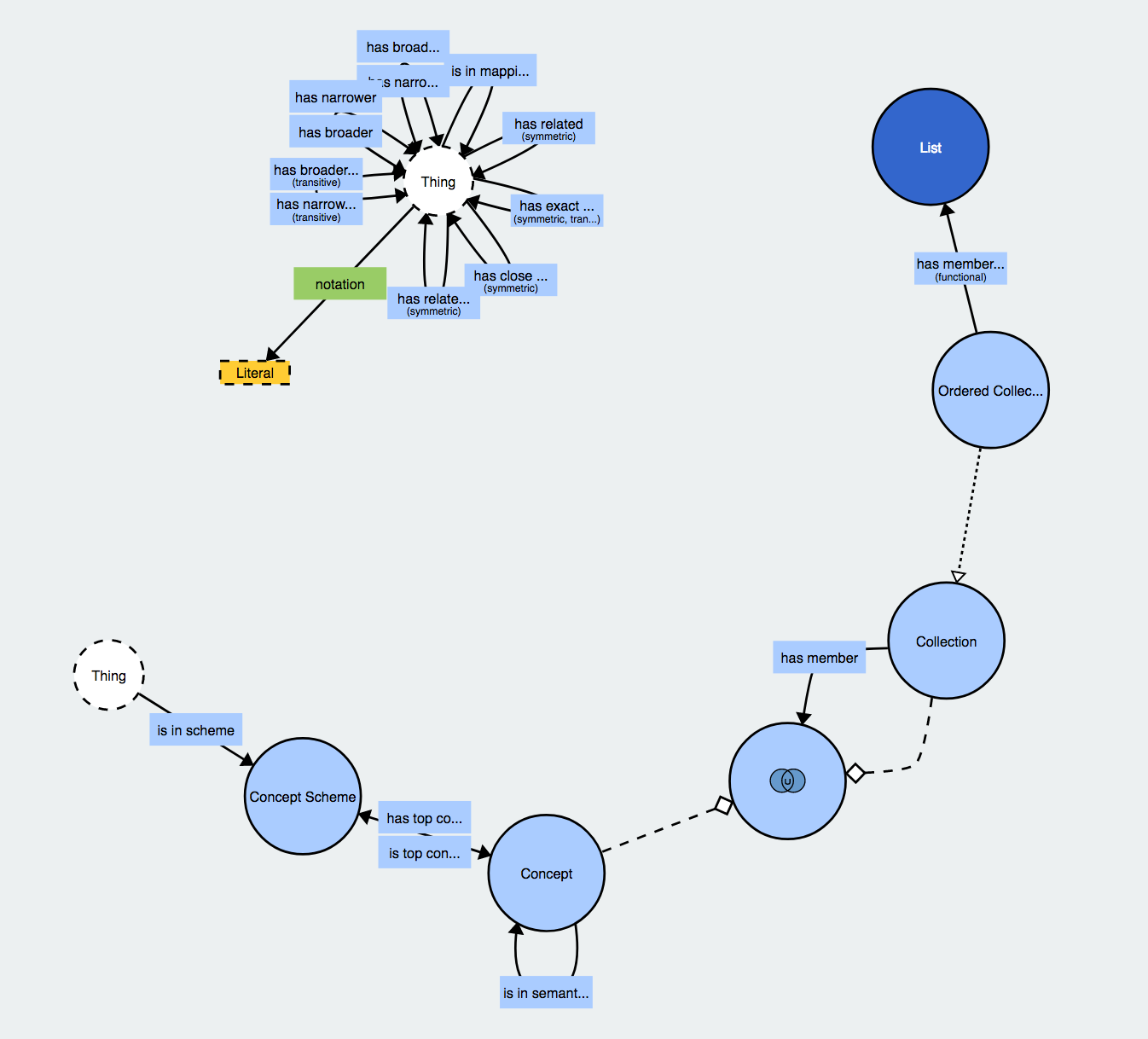
We cast the local administrative units as instances of skos:Concept belonging to the LAU concept scheme.
Using an inline table via the VALUES clause we map the source properties to the target properties from SKOS.
:NAME_1 is mapped to skos:prefLabel, :LAU2_NAT_CODE to skos:notation, and the transliterated names are treated as values of skos:altLabel.
PREFIX : <http://example.com/>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
DELETE {
?lau2 ?source ?o .
}
INSERT {
?lau2 a skos:Concept ;
skos:inScheme <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016> ;
?target ?o .
}
WHERE {
VALUES (?source ?target) {
(:NAME_1 skos:prefLabel)
(:NAME_2_LAT skos:altLabel)
(:LAU2_NAT_CODE skos:notation)
}
?lau2 ?source ?o .
}-
open_withSample RDF output
@prefix : <http://example.com/> . @prefix skos: <http://www.w3.org/2004/02/skos/core#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . [ a skos:Concept ; skos:prefLabel "Alajärvi"@fi ; skos:notation "005" ; skos:inScheme <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016> ; :AREA "1056740000"^^xsd:decimal ; :CHANGE false ; :LAU1_NAT_CODE "146" ; :NUTS_3 "FI194" ; :POP 10006 ; :sheet_name "FI" ] . [ a skos:Concept ; skos:prefLabel "Eura"@fi ; skos:notation "050" ; skos:inScheme <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016> ; :AREA "630200000"^^xsd:decimal ; :CHANGE false ; :LAU1_NAT_CODE "041" ; :NUTS_3 "FI196" ; :POP 12128 ; :sheet_name "FI" ] . [ a skos:Concept ; skos:prefLabel "Petäjävesi"@fi ; skos:notation "592" ; skos:inScheme <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016> ; :AREA "495420000"^^xsd:decimal ; :CHANGE false ; :LAU1_NAT_CODE "131" ; :NUTS_3 "FI193" ; :POP 4008 ; :sheet_name "FI" ] .
We will get back to mapping the statistical part once we generate IRIs of the RDF resources in our data in the next step.