How to generate SPARQL queries via Mustache
You want to generate a SPARQL query dynamically. You can render a Mustache template to SPARQL query and pass it as runtime configuration.
Problem
Consider that you want to generate a SPARQL query based on input data. Configuration of LinkedPipes ETL (LP-ETL) pipelines usually contains static SPARQL queries, but they can be also generated dynamically and passed as runtime configuration. Doing so is useful when a part of a pipeline's configuration is unknown prior to the pipeline's execution. For example, SPARQL queries may need to adapt to the pipeline's input data.
The solution to the problem of generating SPARQL queries can be demonstrated on the integrity constraint 12 (IC-12) from the Data Cube Vocabulary (DCV). DCV is a vocabulary for describing multidimensional datasets composed of observations of statistical phenomena. IC-12 tests if there are no observations sharing the same values of dimensions. In other words, combinations of dimension values must be unique. The original implementation of this constraint present in the DCV specification is generic, albeit slow. Our goal here is to improve the speed of IC-12 by generating a dataset-specific SPARQL query that implements the integrity constraint.
Solution
You can generate SPARQL queries from templates in the Mustache syntax using the Mustache component. Mustache is a widely known minimalistic templating language available in most programming languages. Given a template and data, it renders the template by filling it with the data.
The data model of Mustache is on par with JSON. Since LP-ETL is based on RDF, its implementation of Mustache reads RDF as a JSON-like data structure. RDF referents, including IRIs and blank nodes, are treated as hash maps that contain key-value pairs comprising properties and objects from the triples where the referent is in the subject position. Objects can be either literal values or other referents. Since IRIs are treated as hash maps, if you want to output an IRI, you have to convert it to a literal first. You can do this when you generate the data via the str() function in SPARQL.
Since RDF is structured as a graph while JSON forms a tree, you need to convert RDF into one or more trees for use with Mustache. You can do that by specifying the IRI of the root entity class in the component's configuration. The component will then treat any instance of the given class as a root of a tree. It will render its template for every such instance, which will be used as input data for rendering.
The Mustache component recognizes several special properties from the http://plugins.linkedpipes.com/ontology/t-mustache# namespace, thereafter abbreviated as mustache:.
The mustache:fileName property attached to root entities determines the name of the file in which the output rendered using the data of a given root entity is stored. Since RDF triples are unordered, in case you want objects of an RDF property to be sorted, you must explictly specify their order by numeric indices via the mustache:order property. If you want to distinguish the first object from the rest, you can configure the Mustache component to annotate it by the mustache:first property with the boolean true value. For example, this is useful when you generate lists of items split by a separator.
We generate the input data for the Mustache component from the data structure definition (DSD) of the tested DCV dataset. Among other things, DSDs specify what dimensions are used in DCV datasets conforming to the DSDs. This is what we need to implement IC-12. Dimensions are defined by components of a DSD. The components are enumerated as objects of the qb:component property attached to a given instance of qb:DataStructureDefinition. Dimensions can be distinguished either by being referred via the qb:dimension property or, if referred by the generic qb:componentProperty property, by instantiating the qb:DimensionProperty class. Following this description, we can extract the dimensions from a DSD by using this SPARQL CONSTRUCT query:
PREFIX mustache: <http://plugins.linkedpipes.com/ontology/t-mustache#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX sp: <http://spinrdf.org/sp#>
CONSTRUCT {
?dsd a qb:DataStructureDefinition ;
qb:component [
qb:componentProperty ?dimension ;
sp:varName ?varName
] ;
mustache:fileName ?fileName .
}
WHERE {
?dsd qb:component ?component .
{
?component qb:dimension ?_dimension .
} UNION {
?component qb:componentProperty ?_dimension .
?_dimension a qb:DimensionProperty .
}
BIND (str(?_dimension) AS ?dimension)
BIND (md5(?dimension) AS ?varName)
BIND (concat("ic_12_", md5(str(?dsd)), ".rq") AS ?fileName)
}
As you can see in the query, we use qb:DataStructureDefinition as the root entity class. For each dimension we generate a variable name linked via the sp:varName property. Variable names are derived by hashing the dimensions' IRIs by the md5() hash function because it gives us names conforming to the SPARQL syntax. We will need the variable names for dimensions in our template for IC-12. We pipe the output of this SPARQL query to the Mustache component.
We provide the DSD to the SPARQL CONSTRUCT component by pasting it into the Text holder component and converting it to RDF via the Files to RDF single graph component. This makes the start of our pipeline to look like that:

Now that we have data for the Mustache component, let's turn to its template. The template produces a SPARQL query that tests IC-12. While originally implemented as an ASK query, we reformulated the constraint as a CONSTRUCT query that produces descriptions of observations violating the constraint, instead of merely telling whether the constraint is satisfied or not, as would the ASK query do. The reported violations of IC-12 are described using the SPIN RDF vocabulary. Let's have a look at the template:
{{!
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX sp: <http://spinrdf.org/sp#>
}}
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX spin: <http://spinrdf.org/spin#>
CONSTRUCT {
[] a spin:ConstraintViolation ;
spin:violationRoot ?obs ;
rdfs:label "IC-12" ;
rdfs:comment "No two qb:Observations in the same qb:DataSet may have the same value for all dimensions."@en .
}
WHERE {
{
SELECT {{#qb:component}}
?{{sp:varName}}
{{/qb:component}}
WHERE {
{{#qb:component}}
?obs <{{{qb:componentProperty}}}> ?{{sp:varName}} .
{{/qb:component}}
}
GROUP BY {{#qb:component}}
?{{sp:varName}}
{{/qb:component}}
HAVING (COUNT(?obs) > 1)
}
{{#qb:component}}
?obs <{{{qb:componentProperty}}}> ?{{sp:varName}} .
{{/qb:component}}
}
The Mustache component recognizes an optional leading Mustache comment, delimited by {{! and }}, that defines namespace prefixes using the SPARQL syntax. The defined prefixes can be then used to shorten IRIs of properties referred in Mustache tags. Without prefixes, you would have to use absolute IRIs. In our template, the standard triple curly braces are used to avoid HTML-escaping of IRIs, such as converting & separating query parameters to &. In the component's configuration, we set the Entity class IRI to be qb:DataStructureDefinition via its absolute IRI http://purl.org/linked-data/cube#DataStructureDefinition.
The Mustache component renders files, but runtime configurations must be in RDF. You can use the Files to statements component to convert files to literal objects of a given RDF predicate, in our case http://plugins.linkedpipes.com/ontology/t-sparqlConstruct#query. This component produces a named graph with a single RDF statement for each its input file. In order to work with its output as a single RDF graph, we use the Graph merger component, which simply merges its input named graphs.
You can transform the statements with the rendered queries to a runtime configuration by a SPARQL CONSTRUCT query executed by the SPARQL CONSTRUCT component. The transformation simply types the subject of the generated statement as an instance of the :Configuration class:
PREFIX : <http://plugins.linkedpipes.com/ontology/t-sparqlConstruct#>
PREFIX local: <http://localhost/ontology/>
CONSTRUCT {
local:config a :Configuration ;
:query ?query .
}
WHERE {
[] local:query ?query .
}
Note that blank nodes are not allowed in component configuration. The generated RDF can be used as configuration for another SPARQL CONSTRUCT component. In our case, this component would execute the generated query on a DCV dataset conforming to the input DSD to verify that the dataset adheres to IC-12. Compared to the generic query for IC-12 from the DCV specification, you may see up to 100× speed-up for the generated dataset-specific query.
The pipeline implementing the described process is available here. This is the pipeline's layout:
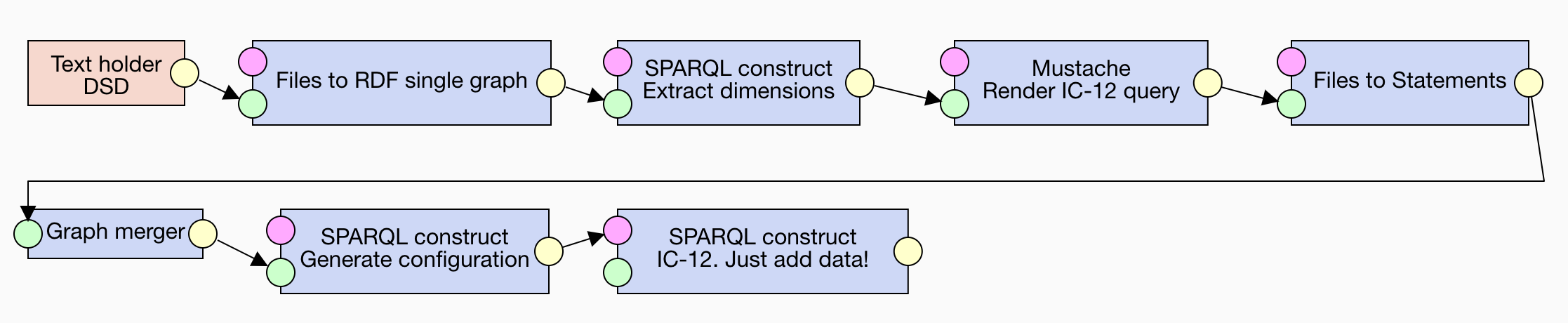
Discussion
Most components in LP-ETL accept runtime configuration in RDF. In this way, LP-ETL pipelines can adapt to the data they process. Dynamic RDF configuration adds an element of homoiconicity to LP-ETL pipelines that enables you to devise novel data processing workflows.
The presented implementation of IC-12 demonstrates only one of this class of workflows. It also shows how two more specific SPARQL queries can be orders of magnitude faster than a single generic query. In cases such as this, a way to optimize a SPARQL query is to decompose it into several simpler and more specific queries.
See also
Validation of DCV's integrity constraints was originally developed as an LP-ETL pipeline fragment for the OpenBudgets.eu project. The implementation of IC-12 showcased in this tutorial comes from this pipeline fragment.