Loading data to Wikibase
In this tutorial, we will walk through the process of preparing a schedulable pipeline for loading data from an external data source to a Wikibase instance such as Wikidata, using LinkedPipes ETL. This was made possible thanks to the Wikimedia Foundation Project Grant Wikidata & ETL. We will demonstrate the process on a pipeline loading basic data about Czech solitary remarkable trees to Wikidata. Note that the tutorial also provides pipeline examples, which can be easily imported into a LinkedPipes ETL instance.
0. Prerequisites
Before we start creating the pipeline, we will go through the prerequisites for the process. For the creation of the pipeline, we need the following, and we provide the values used in this tutorial:
- URL of the target Wikibase instance and its Wikibase API (api.php)
https://www.wikidata.org/w/api.php- URL of the SPARQL endpoint of the query service of the target Wikibase instance
https://query.wikidata.org/sparql- An account with write access to that instance, preferrably with a bot flag and a bot password associated with that account
- LinkedPipes ETL Bot
- Identification of Items used as classes the newly created Items are instances of
Q811534- remarkable treeQ2438638- solitary- Identification of properties to be used in statements, qualifiers and references
P31- instance ofP625- coordinate locationP677- ÚSOP codeP1448- official name- A way of determining, which data record in the source data corresponds to which Item in the Wikibase
- There is an ID in the source, corresponding to
P677- ÚSOP code
1. Getting the source data
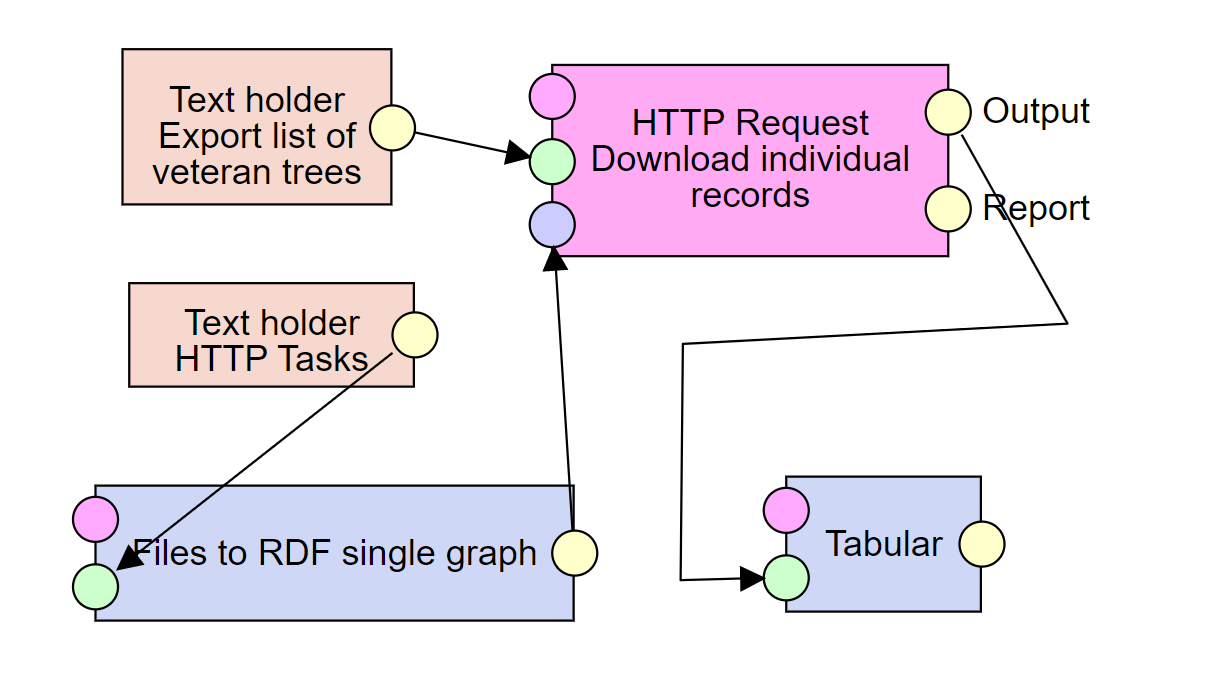
In our case, we will work with the data from the Digital Register of the Nature Conservancy Central Register, accessible to people as a web portal and through a user unfriendly API giving a CSV file. The exact process of getting to the CSV file is out of scope of this tutorial, but it can be seen in our first pipeline fragment, together with the Tabular component, which transforms the data from CSV to RDF according to the CSV on the Web standard.
-
open_withHeader and one row of the CSV file
Kód;Starý kód;Typ objektu;Název;Datum vyhlášení;Datum zrušení;Ochranné pásmo - Typ;Ochranné pásmo - Popis;Počet vyhlášený;Počet skutečný;Poznámka;Souřadnice;Způsob určení souřadnic;Původ souřadnic;Kraj;Okres;Obec s rozšířenou působností;Dat. účinnosti nejnovějšího vyhl. předpisu;Dat vydání nejnovějšího vyhl. předpisu "100001";"811054";"Jednotlivý strom";"Klen nad Českou Vsí";"22.09.2004";"";"ze zákona";"";"1";"1";"Na svažité louce při rozhraní obecní zástavby a lučních porostů, cca 150 m jihovýchodně od kostela";"{X:1048550,08, Y:541804,66} ";"určena poloha všech jednotlivých stromů";"doměřeno, odvozeno z mapy nebo leteckých ortofoto snímků";"Olomoucký";"Olomoucký - Jeseník";"Olomoucký - Jeseník - Jeseník";"22.09.2004";"30.08.2004"
-
open_withRepresentation of the one row in RDF
@prefix csvw: <http://www.w3.org/ns/csvw#> . @prefix ns1: <file://stromy.csv#Obec+s+roz%C5%A1%C3%AD%C5%99enou+p%C5%AFsobnost%C3%AD> . @prefix ns10: <file://stromy.csv#K%C3%B3d> . @prefix ns11: <file://stromy.csv#Ochrann%C3%A9+p%C3%A1smo+-+Typ> . @prefix ns12: <file://stromy.csv#N%C3%A1zev> . @prefix ns13: <file://stromy.csv#Sou%C5%99adnice> . @prefix ns14: <file://stromy.csv#Star%C3%BD+k%C3%B3d> . @prefix ns15: <file://stromy.csv#Zp%C5%AFsob+ur%C4%8Den%C3%AD+sou%C5%99adnic> . @prefix ns16: <file://stromy.csv#Po%C4%8Det+vyhl%C3%A1%C5%A1en%C3%BD> . @prefix ns2: <file://stromy.csv#Pozn%C3%A1mka> . @prefix ns3: <file://stromy.csv#Datum+vyhl%C3%A1%C5%A1en%C3%AD> . @prefix ns4: <file://stromy.csv#Typ+objektu> . @prefix ns5: <file://stromy.csv#P%C5%AFvod+sou%C5%99adnic> . @prefix ns6: <file://stromy.csv#Po%C4%8Det+skute%C4%8Dn%C3%BD> . @prefix ns7: <file://stromy.csv#Dat.+%C3%BA%C4%8Dinnosti+nejnov%C4%9Bj%C5%A1%C3%ADho+vyhl.+p%C5%99edpisu> . @prefix ns8: <file://stromy.csv#Dat+vyd%C3%A1n%C3%AD+nejnov%C4%9Bj%C5%A1%C3%ADho+vyhl.+p%C5%99edpisu> . @prefix ns9: <file://stromy.csv#KrajOkres> . @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . @prefix xml: <http://www.w3.org/XML/1998/namespace> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . <file://stromy.csv> a csvw:Table ; csvw:row [ a csvw:Row ; csvw:describes [ ns8: "30.08.2004" ; ns7: "22.09.2004" ; ns3: "22.09.2004" ; ns10: "100001" ; ns9: "Olomoucký" ; ns12: "Klen nad Českou Vsí" ; ns1: "Olomoucký - Jeseník - Jeseník" ; ns11: "ze zákona" ; ns9: "Olomoucký - Jeseník" ; ns5: "doměřeno, odvozeno z mapy nebo leteckých ortofoto snímků" ; ns6: "1" ; ns16: "1" ; ns2: "Na svažité louce při rozhraní obecní zástavby a lučních porostů, cca 150 m jihovýchodně od kostela" ; ns13: "{X:1048550,08, Y:541804,66} " ; ns14: "811054" ; ns4: "Jednotlivý strom" ; ns15: "určena poloha všech jednotlivých stromů" ] ] .
2. Linked Open Data representation of the data
The next step is to create a Linked Open Data (LOD) representation of the input data.
Data in this form could be, with some additional effort, published as LOD on the Web of Data.
As all structured data published on the Web should ideally be published as LOD, this will be our starting point for the process of loading this data to Wikidata.
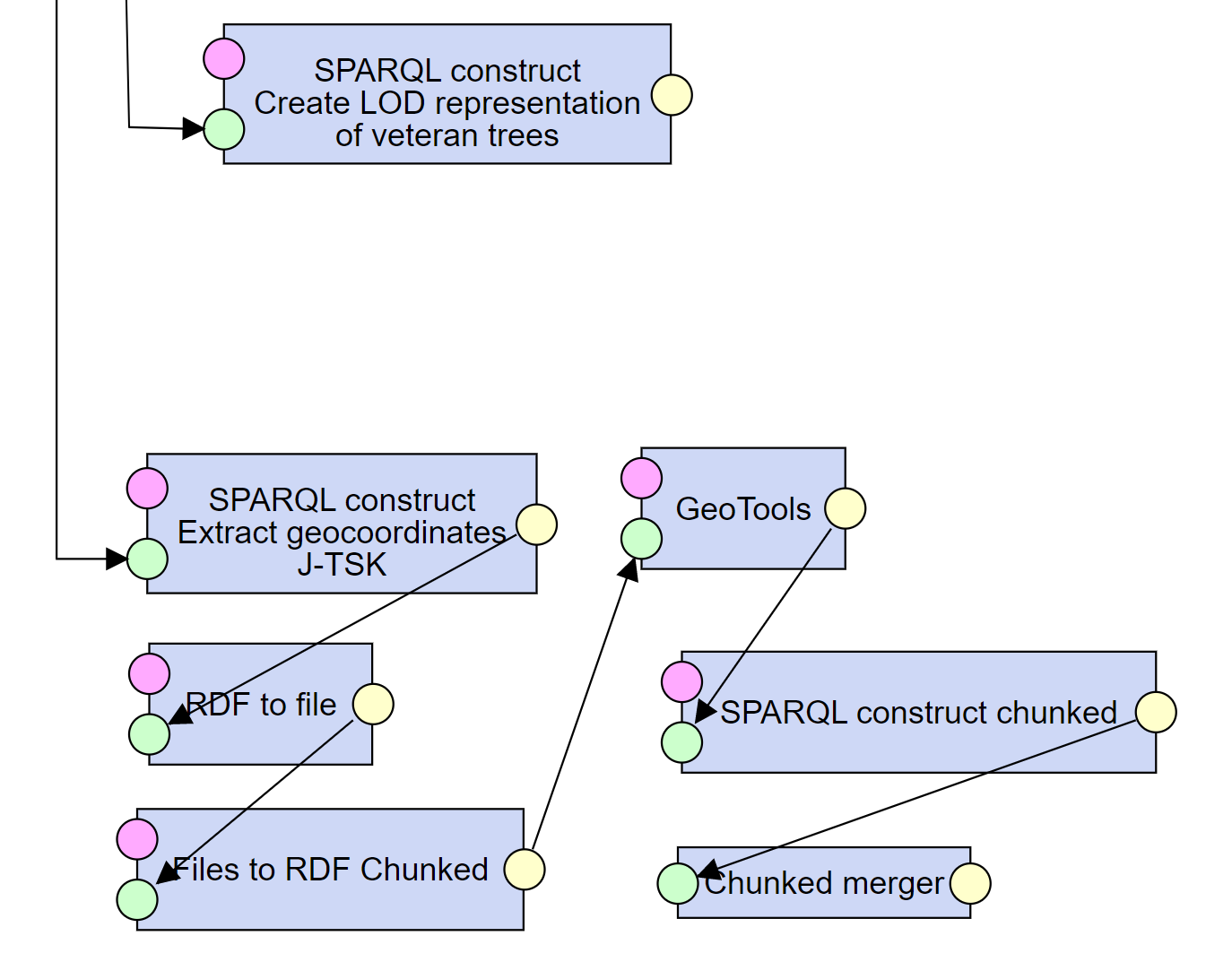
Here, we add a SPARQL construct query, transforming the data to the target LOD vocabularies.
In addition, we use the GeoTools component, which facilitates the conversion of Geocoordinates from one projection to another.
Simply put, we transform the source representation of the coordinates ("{X:1048550,08, Y:541804,66} ") using SPARQL to correct EPSG:5514 representation ("-541804.66 -1048550.08") and then, using GeoTools, to WGS84 (EPSG:4326) ("50.25096013863794 17.224497787399326") representation required by Wikibase.
-
open_withRepresentation of one tree as LOD
<https://drusop.nature.cz/zdroj/památné-stromy/100001> a <http://linkedgeodata.org/ontology/Tree>; <http://schema.org/name> "Klen nad Českou Vsí"@cs; <http://schema.org/startDate> "2004-09-22"^^<http://www.w3.org/2001/XMLSchema#date>; <http://www.w3.org/2004/02/skos/core#notation> "100001"; <urn:okres> "Jeseník"; <urn:počet_skutečný> "1"; <urn:počet_vyhlášený> "1" .
3. Linked Open Data => Wikibase vocabulary
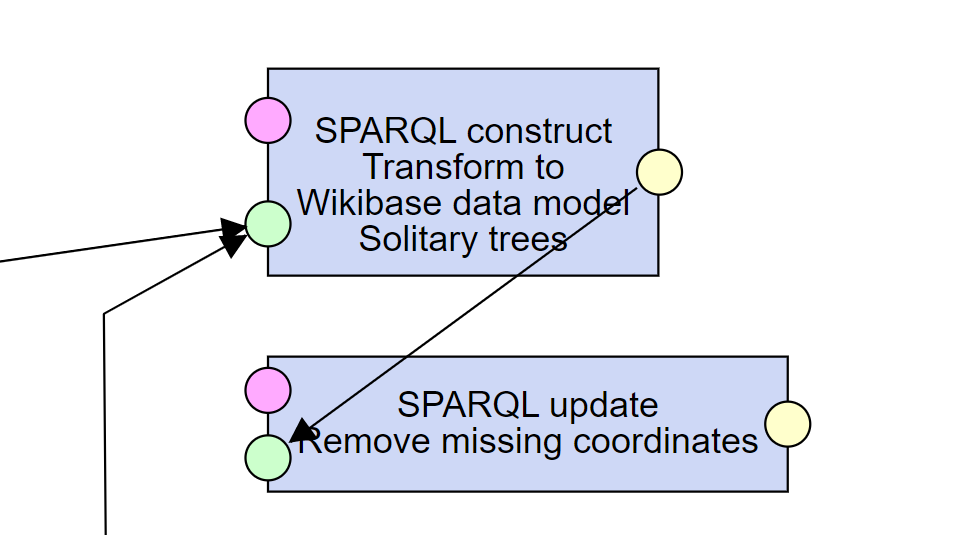
In this step, we take the representation of the data about the remarkable trees as LOD and transform it to the Wikibase vocabulary.
In this case, we use the Wikidata properties mentioned in prerequisites.
We use them to create Items, Statements, Qualifiers, References and Values according to the Wikibase RDF Dump Format.
The transformation is, again, done using a SPARQL construct query.
Note that we mark Items and Statements with a urn:fromSource class, and we store Item labels in urn:nameFromSource and urn:descriptionFromSource, respectively.
This will help us in the next steps to determine which data is already in Wikidata and which needs to be added.
Note that some geocoordinates could be missing, because they were missing in the source. To avoid creating empty geocoordinate values later, we remove those with an additional SPARQL update.
-
open_withSPARQL Construct query used for transformation
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> PREFIX schema: <http://schema.org/> PREFIX wd: <http://www.wikidata.org/entity/> PREFIX so: <http://purl.org/ontology/symbolic-music/> PREFIX prov: <http://www.w3.org/ns/prov#> PREFIX lgdo: <http://linkedgeodata.org/ontology/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX p: <http://www.wikidata.org/prop/> PREFIX ps: <http://www.wikidata.org/prop/statement/> PREFIX pr: <http://www.wikidata.org/prop/reference/> PREFIX pq: <http://www.wikidata.org/prop/qualifier/> PREFIX pqv: <http://www.wikidata.org/prop/qualifier/value/> PREFIX psv: <http://www.wikidata.org/prop/statement/value/> PREFIX new: <http://plugins.linkedpipes.com/ontology/l-wikibase#New> PREFIX fromWikibase: <urn:fromWikiBase> PREFIX fromSource: <urn:fromSource> PREFIX drúsop: <http://www.wikidata.org/entity/Q26778346> PREFIX veteran: <http://www.wikidata.org/entity/Q811534> PREFIX : <urn:> CONSTRUCT { ?strom a wikibase:Item, fromSource: ; <urn:nameFromSource> ?label ; <urn:descriptionFromSource> ?description ; p:P677 ?s_677 ; p:P31 ?s_31_tree, ?s_31_subtype ; p:P625 ?s_625 ; p:P1448 ?s_1448_statement . ?s_677 a wikibase:Statement, fromSource: ; #P677 - ÚSOP code ps:P677 ?id ; prov:wasDerivedFrom ?ref_s_677 . ?s_31_tree a wikibase:Statement, fromSource: ; #P31 instance of ps:P31 veteran: ; #P580 start time pqv:P580 ?q_580 ; prov:wasDerivedFrom ?ref_s_31 . ?q_580 a wikibase:TimeValue ; wikibase:timeValue ?startDateDT ; wikibase:timePrecision "11"^^xsd:integer ; wikibase:timeTimezone "0"^^xsd:integer ; wikibase:timeCalendarModel <http://www.wikidata.org/entity/Q1985727> . ?s_31_subtype a wikibase:Statement, fromSource: ; #P31 instance of ps:P31 ?typq ; prov:wasDerivedFrom ?ref_s_31 . ?ref_s_677 a wikibase:Reference, fromSource: ; #P248 - stated in pr:P248 drúsop: . ?ref_s_31 a wikibase:Reference, fromSource: ; #P248 - stated in pr:P248 drúsop: . ?s_625 a wikibase:Statement, fromSource: ; #P625 - coordinate location psv:P625 ?v_625 ; prov:wasDerivedFrom ?ref_s_625 . ?ref_s_625 a wikibase:Reference, fromSource: ; #P248 - stated in pr:P248 drúsop: . ?v_625 a wikibase:GlobecoordinateValue ; wikibase:geoLatitude ?lat_double ; wikibase:geoLongitude ?lon_double ; wikibase:geoPrecision "1.0E-6"^^xsd:double ; wikibase:geoGlobe <http://www.wikidata.org/entity/Q2> . ?s_1448_statement a wikibase:Statement, fromSource: ; ps:P1448 ?label ; prov:wasDerivedFrom ?ref_s_1448 . ?ref_s_1448 a wikibase:Reference, fromSource: ; #P248 - stated in pr:P248 drúsop: . } WHERE { ?strom a ?typ ; schema:name ?label ; skos:notation ?id ; :okres ?okr . OPTIONAL { ?strom schema:startDate ?startDate } OPTIONAL { ?strom schema:geo ?geo . ?geo schema:longitude ?lon ; schema:latitude ?lat . } VALUES(?typ ?typq) { (lgdo:Tree wd:Q2438638) } BIND(STR(?strom) as ?strom_txt) BIND(STRDT(CONCAT(STR(?startDate), "T00:00:00Z"),xsd:dateTime) AS ?startDateDT) BIND(STRLANG(CONCAT("Památný strom v okrese ", ?okr, ", kód ÚSOP ", ?id), "cs") as ?description) #This causes the qualifier not to be present when there is no ?startDate - the IRI is not bound BIND(IRI(CONCAT("urn:", STR(?startDate))) as ?q_580) BIND(UUID() as ?s_677) BIND(UUID() as ?s_31_tree) BIND(UUID() as ?s_31_subtype) BIND(UUID() as ?s_1448_statement) BIND(UUID() as ?ref_s_677) BIND(UUID() as ?ref_s_31) BIND(UUID() as ?ref_s_1448) BIND(UUID() as ?s_625) BIND(UUID() as ?ref_s_625) BIND(UUID() as ?v_625) BIND(STRDT(?lat, xsd:double) as ?lat_double) BIND(STRDT(?lon, xsd:double) as ?lon_double) BIND(UUID() as ?val) }
-
open_withRepresentation of one tree using Wikidata RDF Dump Format
<https://drusop.nature.cz/zdroj/památné-stromy/100001> a <http://wikiba.se/ontology#Item>, <urn:fromSource>; <http://www.wikidata.org/prop/P1448> <urn:uuid:b929dccb-8417-4fd6-8ee8-70e3b4d22d18>; <http://www.wikidata.org/prop/P31> <urn:uuid:2e4fa998-11c4-4845-89e0-047d74d6189d>, <urn:uuid:7f9688b6-8336-48f1-b1d7-e792d526118c>; <http://www.wikidata.org/prop/P625> <urn:uuid:44d45043-e2cd-4087-90db-62d5de83849d>; <http://www.wikidata.org/prop/P677> <urn:uuid:36745307-57f5-4029-bcbb-f97564672e42>; <urn:descriptionFromSource> "Památný strom v okrese Jeseník, kód ÚSOP 100001"@cs; <urn:nameFromSource> "Klen nad Českou Vsí"@cs . <urn:uuid:36745307-57f5-4029-bcbb-f97564672e42> a <http://wikiba.se/ontology#Statement>, <urn:fromSource>; <http://www.w3.org/ns/prov#wasDerivedFrom> <urn:uuid:dae823b0-3ebd-4d76-ba39-9c93491fd22d>; <http://www.wikidata.org/prop/statement/P677> "100001" . <urn:uuid:7f9688b6-8336-48f1-b1d7-e792d526118c> a <http://wikiba.se/ontology#Statement>, <urn:fromSource>; <http://www.w3.org/ns/prov#wasDerivedFrom> <urn:uuid:de8913c7-6620-41e8-a3d1-d29d64f4da92>; <http://www.wikidata.org/prop/qualifier/value/P580> <urn:2004-09-22>; <http://www.wikidata.org/prop/statement/P31> <http://www.wikidata.org/entity/Q811534> . <urn:2004-09-22> a <http://wikiba.se/ontology#TimeValue>; <http://wikiba.se/ontology#timeCalendarModel> <http://www.wikidata.org/entity/Q1985727>; <http://wikiba.se/ontology#timePrecision> 11; <http://wikiba.se/ontology#timeTimezone> 0; <http://wikiba.se/ontology#timeValue> "2004-09-22T00:00:00Z"^^<http://www.w3.org/2001/XMLSchema#dateTime> . <urn:uuid:2e4fa998-11c4-4845-89e0-047d74d6189d> a <http://wikiba.se/ontology#Statement>, <urn:fromSource>; <http://www.w3.org/ns/prov#wasDerivedFrom> <urn:uuid:de8913c7-6620-41e8-a3d1-d29d64f4da92>; <http://www.wikidata.org/prop/statement/P31> <http://www.wikidata.org/entity/Q2438638> . <urn:uuid:dae823b0-3ebd-4d76-ba39-9c93491fd22d> a <http://wikiba.se/ontology#Reference>, <urn:fromSource>; <http://www.wikidata.org/prop/reference/P248> <http://www.wikidata.org/entity/Q26778346> . <urn:uuid:de8913c7-6620-41e8-a3d1-d29d64f4da92> a <http://wikiba.se/ontology#Reference>, <urn:fromSource>; <http://www.wikidata.org/prop/reference/P248> <http://www.wikidata.org/entity/Q26778346> . <urn:uuid:44d45043-e2cd-4087-90db-62d5de83849d> a <http://wikiba.se/ontology#Statement>, <urn:fromSource>; <http://www.w3.org/ns/prov#wasDerivedFrom> <urn:uuid:c07c6210-e428-4cb8-904f-44c66907b8e7>; <http://www.wikidata.org/prop/statement/value/P625> <urn:uuid:957eb57b-9b8d-45b4-b06e-0d64bcc6832c> . <urn:uuid:c07c6210-e428-4cb8-904f-44c66907b8e7> a <http://wikiba.se/ontology#Reference>, <urn:fromSource>; <http://www.wikidata.org/prop/reference/P248> <http://www.wikidata.org/entity/Q26778346> . <urn:uuid:957eb57b-9b8d-45b4-b06e-0d64bcc6832c> a <http://wikiba.se/ontology#GlobecoordinateValue>; <http://wikiba.se/ontology#geoGlobe> <http://www.wikidata.org/entity/Q2>; <http://wikiba.se/ontology#geoLatitude> 5.025096013863794E1; <http://wikiba.se/ontology#geoLongitude> 1.7224497787399326E1; <http://wikiba.se/ontology#geoPrecision> 1.0E-6 . <urn:uuid:b929dccb-8417-4fd6-8ee8-70e3b4d22d18> a <http://wikiba.se/ontology#Statement>, <urn:fromSource>; <http://www.w3.org/ns/prov#wasDerivedFrom> <urn:uuid:ef40c09c-db41-4399-be27-747782a33227>; <http://www.wikidata.org/prop/statement/P1448> "Klen nad Českou Vsí"@cs . <urn:uuid:ef40c09c-db41-4399-be27-747782a33227> a <http://wikiba.se/ontology#Reference>, <urn:fromSource>; <http://www.wikidata.org/prop/reference/P248> <http://www.wikidata.org/entity/Q26778346> .
4. Querying Wikibase for existing data
In this step, we query the Wikidata Query Service for existing data about Czech remarkable trees.
To identify all Czech remarkable trees, we query for all Items having the P677 - ÚSOP code property - this is a unique code used in the source registry to identify the remarkable trees.
In addition, we query for all data (statements) about the remarkable trees that we work with in this pipeline so that we can determine, which are already in Wikidata and which need to be created.
Note that we mark Items and Statements with a urn:fromWikiBase class, and we store Item labels in urn:nameFromWiki and urn:descriptionFromWikibase, respectively.
This will help us in the next steps to determine which data is already in Wikidata and which needs to be added.
Note that in fact, this code is also used for other objects, but this won't actually matter, because we use the result of the query later only to determine, which items from the source are already in Wikidata. Therefore, it will not matter that there are also some additional items in the query result.

-
open_withSPARQL query to get existing data from Wikidata
PREFIX psv: <http://www.wikidata.org/prop/statement/value/> PREFIX schema: <http://schema.org/> PREFIX sc: <http://purl.org/science/owl/sciencecommons/> PREFIX wd: <http://www.wikidata.org/entity/> PREFIX prov: <http://www.w3.org/ns/prov#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX p: <http://www.wikidata.org/prop/> PREFIX ps: <http://www.wikidata.org/prop/statement/> PREFIX pr: <http://www.wikidata.org/prop/reference/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX wdt: <http://www.wikidata.org/prop/direct/> PREFIX pqv: <http://www.wikidata.org/prop/qualifier/value/> PREFIX fromWikibase: <urn:fromWikiBase> PREFIX drúsop: <http://www.wikidata.org/entity/Q26778346> PREFIX veteran: <http://www.wikidata.org/entity/Q811534> PREFIX solitary: <http://www.wikidata.org/entity/Q2438638> CONSTRUCT { ?item a wikibase:Item, fromWikibase: ; <urn:nameFromWiki> ?label ; <urn:descriptionFromWikibase> ?description ; p:P31 ?p31_statement ; p:P677 ?p677_statement ; p:P2670 ?p2670_statement ; p:P625 ?p625_statement ; p:P1448 ?p1448_statement . ?p677_statement a wikibase:Statement, fromWikibase: ; ps:P677 ?p677_value ; prov:wasDerivedFrom ?p677_ref. ?p677_ref a wikibase:Reference, fromWikibase: ; pr:P248 ?p677r248_value . ?p31_statement a wikibase:Statement, fromWikibase: ; ps:P31 ?p31_value ; prov:wasDerivedFrom ?p31_ref ; pqv:P580 ?s31_q580 . ?s31_q580 a wikibase:TimeValue ; ?tvp ?tvo . ?p31_ref a wikibase:Reference, fromWikibase: ; pr:P248 ?p31r248_value . ?p2670_statement a wikibase:Statement, fromWikibase: ; ps:P2670 ?p2670_value ; prov:wasDerivedFrom ?p2670_ref ; pqv:P1114 ?q_1114 . ?p2670_ref a wikibase:Reference, fromWikibase: ; pr:P248 ?p2670r248_value . ?q_1114 a wikibase:QuantityValue ; wikibase:quantityAmount ?počet_decimal ; wikibase:quantityUnit ?qu . ?p625_statement a wikibase:Statement, fromWikibase: ; psv:P625 ?p625_value ; prov:wasDerivedFrom ?p625_ref . ?p625_value a wikibase:GlobecoordinateValue ; wikibase:geoLatitude ?lat ; wikibase:geoLongitude ?lon ; wikibase:geoPrecision ?precision ; wikibase:geoGlobe ?globe . ?p625_ref pr:P248 ?p625r248_value . ?p1448_statement a wikibase:Statement, fromWikibase: ; ps:P1448 ?p1448_value . } WHERE { ?item #P677 - ÚSOP code p:P677 ?p677_statement . #wdt:P31 veteran:, solitary: . OPTIONAL { ?item rdfs:label ?label . FILTER(lang(?label) = "cs") } OPTIONAL { ?item schema:description ?description . FILTER(lang(?description) = "cs") } #ÚSOP code ?p677_statement ps:P677 ?p677_value . #ÚSOP code reference OPTIONAL { ?p677_statement prov:wasDerivedFrom ?p677_ref. ?p677_ref pr:P248 ?p677r248_value . } #P1448 - official name OPTIONAL { ?item p:P1448 ?p1448_statement . ?p1448_statement ps:P1448 ?p1448_value . } #Solitary, alley or grove OPTIONAL { #P31 instance of ?item p:P31 ?p31_statement . ?p31_statement ps:P31 ?p31_value . OPTIONAL { ?p31_statement prov:wasDerivedFrom ?p31_ref . #P248 - stated in ?p31_ref pr:P248 ?p31r248_value . } OPTIONAL { ?p31_statement pqv:P580 ?s31_q580 . ?s31_q580 a wikibase:TimeValue ; ?tvp ?tvo . } } OPTIONAL { #P625 - coordinate location ?item p:P625 ?p625_statement . ?p625_statement psv:P625 ?p625_value . ?p625_value a wikibase:GlobecoordinateValue ; wikibase:geoLatitude ?lat ; wikibase:geoLongitude ?lon ; wikibase:geoPrecision ?precision ; wikibase:geoGlobe ?globe . OPTIONAL { ?p625_statement prov:wasDerivedFrom ?p625_ref. #P248 - stated in ?p625_ref pr:P248 ?p625r248_value . } } }
-
open_withData about one tree from Wikibase Query Service
<http://www.wikidata.org/entity/Q11706514> a <http://wikiba.se/ontology#Item>, <urn:fromWikiBase>; <http://www.wikidata.org/prop/P31> <http://www.wikidata.org/entity/statement/Q11706514-92E7B4FB-7406-48A7-866B-1FA27278FBBE>; <http://www.wikidata.org/prop/P625> <http://www.wikidata.org/entity/statement/Q11706514-F4FF1E70-343D-4681-8271-F1983DCE70F1>; <http://www.wikidata.org/prop/P677> <http://www.wikidata.org/entity/statement/q11706514-20748C49-5849-46E2-8E07-AA9D77F932BE>; <urn:descriptionFromWikibase> "přírodní památka v Česku"@cs; <urn:nameFromWiki> "Bílá hora"@cs . <http://www.wikidata.org/entity/statement/q11706514-20748C49-5849-46E2-8E07-AA9D77F932BE> a <http://wikiba.se/ontology#Statement>, <urn:fromWikiBase>; <http://www.wikidata.org/prop/statement/P677> "1627" . <http://www.wikidata.org/entity/statement/Q11706514-92E7B4FB-7406-48A7-866B-1FA27278FBBE> a <http://wikiba.se/ontology#Statement>, <urn:fromWikiBase>; <http://www.w3.org/ns/prov#wasDerivedFrom> <http://www.wikidata.org/reference/2c919f4317bb7b24dad261d8fbe486327f37cf97>; <http://www.wikidata.org/prop/statement/P31> <http://www.wikidata.org/entity/Q21100463> . <http://www.wikidata.org/reference/2c919f4317bb7b24dad261d8fbe486327f37cf97> a <http://wikiba.se/ontology#Reference>, <urn:fromWikiBase>; <http://www.wikidata.org/prop/reference/P248> <http://www.wikidata.org/entity/Q26778346> . <http://www.wikidata.org/entity/statement/Q11706514-F4FF1E70-343D-4681-8271-F1983DCE70F1> a <http://wikiba.se/ontology#Statement>, <urn:fromWikiBase>; <http://www.w3.org/ns/prov#wasDerivedFrom> <http://www.wikidata.org/reference/5892dbddf63a1df2ea9a21c561e969e76a14fab4>; <http://www.wikidata.org/prop/statement/value/P625> <http://www.wikidata.org/value/45e356f962134e5135458a70ab3656a5> . <http://www.wikidata.org/value/45e356f962134e5135458a70ab3656a5> a <http://wikiba.se/ontology#GlobecoordinateValue>; <http://wikiba.se/ontology#geoGlobe> <http://www.wikidata.org/entity/Q2>; <http://wikiba.se/ontology#geoLatitude> 4.9192947222222E1; <http://wikiba.se/ontology#geoLongitude> 1.6661411666667E1; <http://wikiba.se/ontology#geoPrecision> 2.7777777777778E-7 . <http://www.wikidata.org/reference/5892dbddf63a1df2ea9a21c561e969e76a14fab4> <http://www.wikidata.org/prop/reference/P248> <http://www.wikidata.org/entity/Q12035233> .
5. Resolving existing Wikidata Items
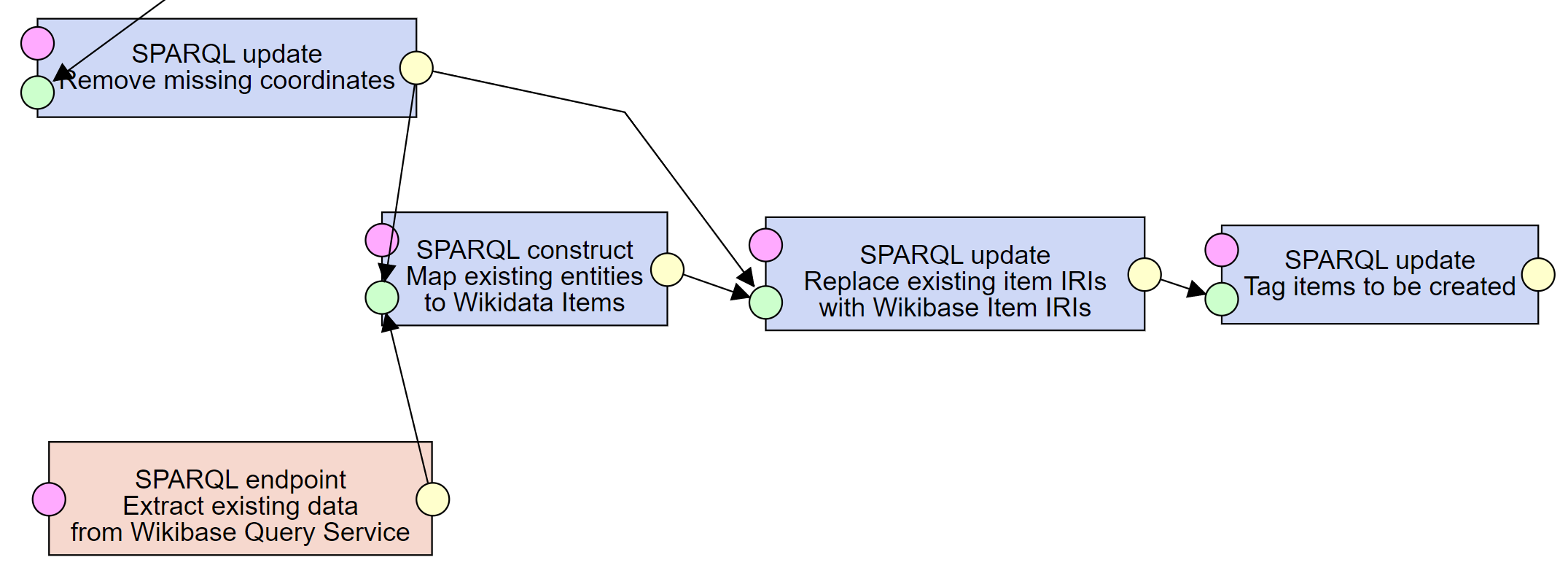
We have the data from the data source transformed to the Wikidata RDF Dump Format, and we also have all the data already in Wikidata in the same format from the Query Service.
The next step towards being able to load the updated data into Wikibase is to match the Items from our source data to existing Items from the Query Service.
We do that in three steps.
First, we create owl:sameAs links between Items from the data source and corresponding Items from Wikidata.
Second, we replace the IRIs of the source Items with IRIs of the found corresponding ones from Wikidata.
Third, for those Items not found in Wikidata, we add the loader:New class, marking the Item to be created in Wikidata.
-
open_withSPARQL Construct query generating owl:sameAs links between corresponding Items
PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX p: <http://www.wikidata.org/prop/> PREFIX ps: <http://www.wikidata.org/prop/statement/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX fromWikibase: <urn:fromWikiBase> PREFIX fromSource: <urn:fromSource> CONSTRUCT { ?item owl:sameAs ?minexisting . } WHERE { #The aggregation is to make sure we don't have duplicities SELECT ?item (MIN(?existing) as ?minexisting) WHERE { ?item a fromSource: ; p:P677 ?p677_statement . ?p677_statement ps:P677 ?p677_value . ?existing a fromWikibase: ; p:P677 ?p677_statement_wb . ?p677_statement_wb ps:P677 ?p677_value . } GROUP BY ?item }
-
open_withSPARQL Update query attaching Wikidata Item IRIs to corresponding source Items
PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX fromSource: <urn:fromSource> DELETE { ?sourceItem ?p ?o . } INSERT { ?wikiItem ?p ?o . } WHERE { ?sourceItem a wikibase:Item, fromSource: ; owl:sameAs ?wikiItem ; ?p ?o . }
-
open_withSPARQL Update query attaching create tags to Items to be created in Wikidata
PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX fromSource: <urn:fromSource> PREFIX new: <http://plugins.linkedpipes.com/ontology/l-wikibase#New> INSERT { ?sourceItem a new: } WHERE { ?sourceItem a wikibase:Item, fromSource: . FILTER NOT EXISTS { ?sourceItem owl:sameAs ?wikiItem } }
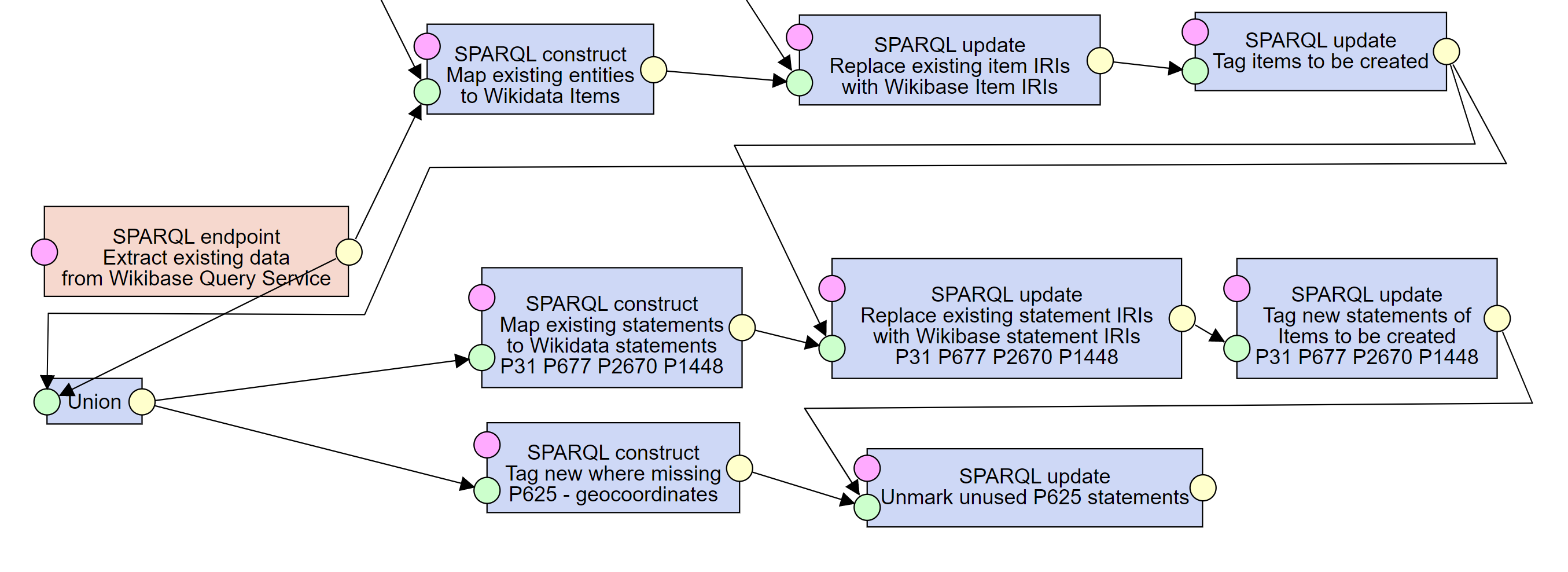
6. Resolving existing Wikidata Statements
For the Items already existing in Wikibase (now tagged with both urn:fromWikiBase and urn:fromSource classes) we need to determine, which of their Statements are already in Wikibase and which need to be created.
We do this again in three steps, the same as with Items.
First, we create owl:sameAs links between Statements from the data source and corresponding Statements from Wikidata.
In this instance, we say that two Statements are the same, when they use the same Property and have the same Value.
Second, we replace the IRIs of the source Statements with IRIs of the found corresponding ones from Wikidata.
Third, for those Statements not found in Wikidata, we add the loader:New class, marking the Statements to be created in Wikidata.
Note that for P625 - coordinate location we adopt a simpler technique.
We simply check whether there is already a Statement with a set of coordinates in Wikidata for a given Item.
If there already is one, we do not want to overwrite it in Wikidata at this time, so we remove the wikibase:Statement class from the Statement, making it ignored.
-
open_withSPARQL Construct query generating owl:sameAs links between corresponding Statements
PREFIX prov: <http://www.w3.org/ns/prov#> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX p: <http://www.wikidata.org/prop/> PREFIX pr: <http://www.wikidata.org/prop/reference/> PREFIX ps: <http://www.wikidata.org/prop/statement/> PREFIX fromWikibase: <urn:fromWikiBase> PREFIX fromSource: <urn:fromSource> CONSTRUCT { ?sourceStatement owl:sameAs ?wikiStatement . } WHERE { ?item a wikibase:Item; ?p ?sourceStatement ; ?p ?wikiStatement . ?sourceStatement a wikibase:Statement, fromSource: ; ?ps ?value . ?wikiStatement a wikibase:Statement, fromWikibase: ; ?ps ?value . VALUES (?p ?ps) { (p:P31 ps:P31) (p:P677 ps:P677) (p:P2670 ps:P2670) (p:P1448 ps:P1448) } }
-
open_withSPARQL Update query attaching Wikidata Statement IRIs to corresponding source Statements
PREFIX ps: <https://w3id.org/payswarm#> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX p: <http://www.wikidata.org/prop/> PREFIX wikibase: <http://wikiba.se/ontology#> DELETE { ?item ?statementProperty ?sourceStatement . ?sourceStatement ?p ?o . } INSERT { ?item ?statementProperty ?wikiStatement . ?wikiStatement ?p ?o . } WHERE { ?item a wikibase:Item ; ?statementProperty ?sourceStatement . ?sourceStatement a wikibase:Statement ; owl:sameAs ?wikiStatement ; ?p ?o . VALUES (?statementProperty) { (p:P31) (p:P677) (p:P2670) (p:P1448) } }
-
open_withSPARQL Update query attaching create tags to Statements to be created in Wikidata
PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX p: <http://www.wikidata.org/prop/> PREFIX new: <http://plugins.linkedpipes.com/ontology/l-wikibase#New> INSERT { ?statement a new: } WHERE { ?sourceItem a wikibase:Item ; ?p ?statement . ?statement a wikibase:Statement . VALUES ?p { p:P31 p:P677 p:P2670 p:P1448} FILTER NOT EXISTS { ?statement a wikibase:Statement ; owl:sameAs ?wikiStatement . } }
7. Resolving labels and descriptions
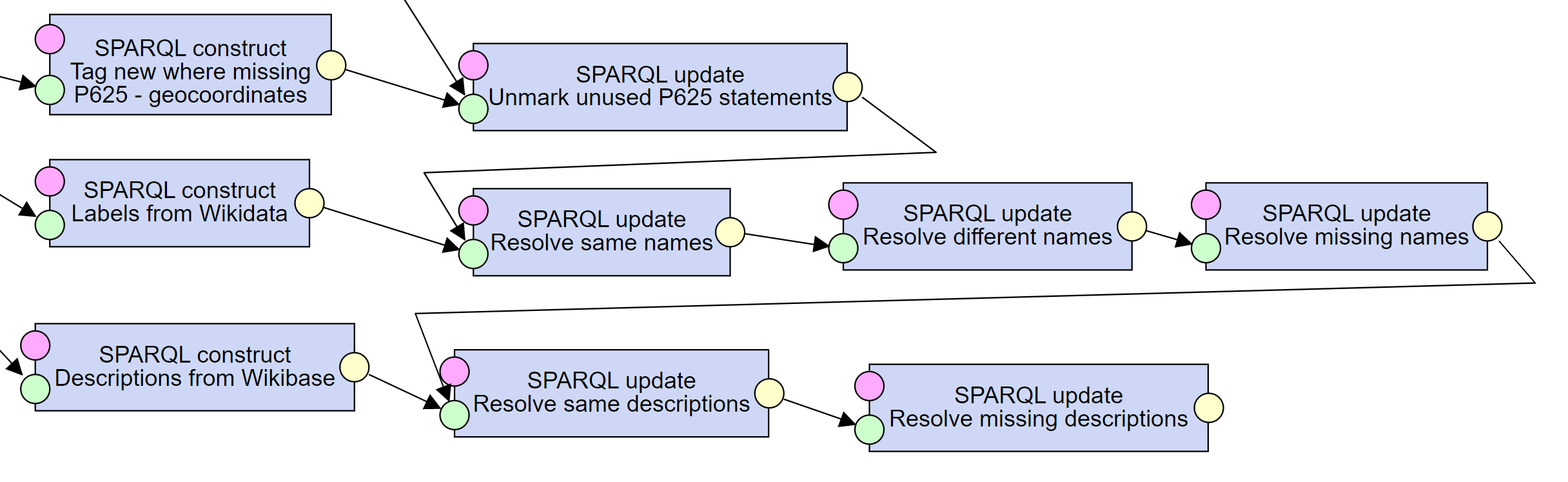
To deal with labels, we proceed in four steps. First, we pass the labels found in Wikidata Query Service, so that we can work with them. Second, we remove (therefore ignore) those, which are the same as the ones from the data source - there is nothing to do in this case. Third, due to Wikidata best practices, if the source label differs from the one found in Wikidata, we attach the source label as an alias. Finally, for Items which have no label in Wikidata, we add it.
Note that we follow a similar approach for descriptions, except there are no aliases in descriptions. Therefore, we add a description only if one is missing in Wikidata.
-
open_withSPARQL Construct query passing Item labels from Wikidata
PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX fromWikibase: <urn:fromWikiBase> PREFIX fromSource: <urn:fromSource> CONSTRUCT WHERE { ?item a wikibase:Item, fromWikibase:, fromSource: ; <urn:nameFromWiki> ?label . }
-
open_withSPARQL Update query removing labels already present in Wikidata
PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX schema: <http://schema.org/> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX p: <http://www.wikidata.org/prop/> PREFIX fromWikibase: <urn:fromWikiBase> PREFIX fromSource: <urn:fromSource> PREFIX new: <http://plugins.linkedpipes.com/ontology/l-wikibase#New> #no need to insert since we do not want to change anything DELETE { ?item <urn:nameFromSource> ?name ; <urn:nameFromWiki> ?name . } WHERE { ?item a wikibase:Item, fromSource:, fromWikibase: ; <urn:nameFromSource> ?name . ?item a wikibase:Item, fromSource:, fromWikibase: ; <urn:nameFromWiki> ?name . }
-
open_withSPARQL Update query resolving labels which are different from those in Wikidata
PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX schema: <http://schema.org/> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX p: <http://www.wikidata.org/prop/> PREFIX fromWikibase: <urn:fromWikiBase> PREFIX fromSource: <urn:fromSource> PREFIX new: <http://plugins.linkedpipes.com/ontology/l-wikibase#New> DELETE { ?item <urn:nameFromSource> ?sourceName ; <urn:nameFromWiki> ?wikiName . } INSERT { ?item skos:altLabel ?sourceName . } WHERE { ?item a wikibase:Item, fromSource: ; <urn:nameFromSource> ?sourceName . #they are different - same names are dealt with in the previous query ?item a fromWikibase: ; <urn:nameFromWiki> ?wikiName . }
-
open_withSPARQL Update query resolving labels which are missing in Wikidata
PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX schema: <http://schema.org/> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX p: <http://www.wikidata.org/prop/> PREFIX fromWikibase: <urn:fromWikiBase> PREFIX fromSource: <urn:fromSource> PREFIX new: <http://plugins.linkedpipes.com/ontology/l-wikibase#New> DELETE { ?item <urn:nameFromSource> ?sourceName . } INSERT { ?item schema:name ?sourceName . } WHERE { ?item a wikibase:Item, fromSource: ; <urn:nameFromSource> ?sourceName . FILTER NOT EXISTS { ?item a fromWikibase: ; <urn:nameFromWiki> ?wikiName . } }
8. Loading data into Wikibase
Now we have the data ready to be loaded to Wikidata.
Before we do that, we remove all remaining owl:sameAs and similar tags, but it is not necessary.
We load the data using the configured Wikibase loader component.
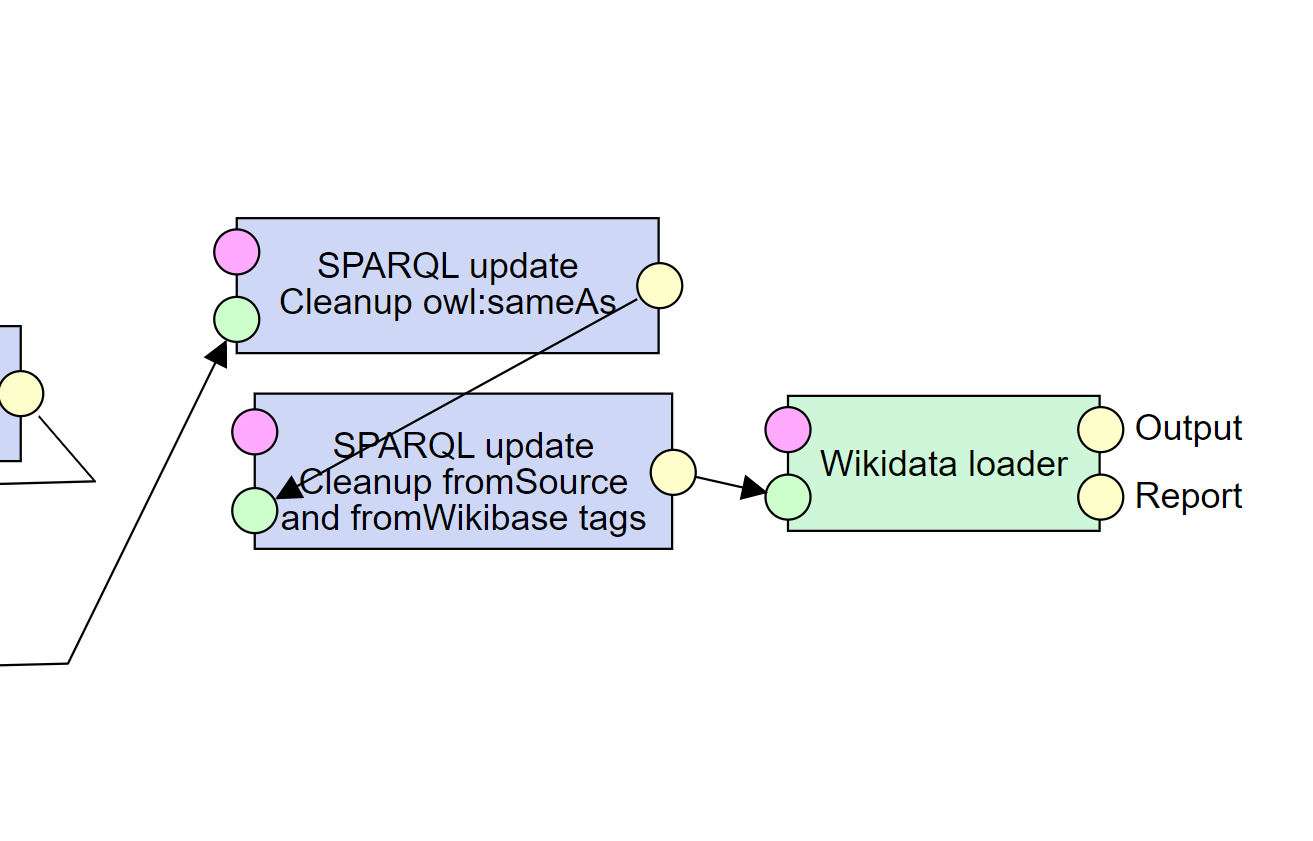
9. Checking for errors
Finally, in the Report output of the Wikibase loader, we can check for any errors encountered while loading.
In addition, in the Output output of the loader, we can see the Q ids of the newly created Items for future use.
The contributions of the bot should also be checked.
Tips, Tricks and Experiences
Here we list some observations we gathered during our project, which may be helpful to others.
Resuming pipeline execution side-effects
Note that LP-ETL provides debugging support in the form of the ability to resume failed or cancelled pipeline execution. When loading data to Wikidata, this may have an undesirable side-effect. When we determine which Items and Statements we want to create, we do that based on the status of the Wikibase instance. When those Items are created in the Wikibase, we cannot simply change something in the pipeline and run it again without again querying the Wikibase. If we would do that, we would again create the already created Items, creating undesirable duplicates.
Generating complex data values
According to the Wikibase RDF Dump Format, complex values such as wikibase:GlobecoordinateValue, have more items than usual in the data currently available on the web.
This leads to the need to generate these additional items such as wikibase:geoPrecision and wikibase:geoGlobe as constants e.g. in SPARQL.
In case where there is no data for the geocoordinate, the constants are then generated anyway, leading to undesired empty values.
In that case, an additional SPARQL Update query can be used to clean up the representations with no actual values.
-
open_withSample of wikibase:GlobecoordinateValue in RDF
v:227fc74c25882e4f3f99399dedc4ce3f a wikibase:GlobecoordinateValue ; wikibase:geoLatitude "50.22031784"^^xsd:double ; wikibase:geoLongitude "14.15890026"^^xsd:double ; wikibase:geoPrecision "0.014039747329343"^^xsd:double ; wikibase:geoGlobe <http://www.wikidata.org/entity/Q2> .
-
open_withSPARQL CONSTRUCT query for generating geocoordinates
CONSTRUCT { ?geo a wikibase:GlobecoordinateValue ; wikibase:geoLatitude ?lat_double ; wikibase:geoLongitude ?lon_double ; wikibase:geoPrecision "1.0E-6"^^xsd:double ; wikibase:geoGlobe <http://www.wikidata.org/entity/Q2> . } WHERE { ?tree a ?type . OPTIONAL { ?tree schema:geo ?geo . ?geo schema:longitude ?lon ; schema:latitude ?lat . } BIND(STRDT(?lat, xsd:double) as ?lat_double) BIND(STRDT(?lon, xsd:double) as ?lon_double) }
-
open_withSample of wikibase:GlobecoordinateValue with missing properties
<urn:value> a wikibase:GlobecoordinateValue ; wikibase:geoPrecision "1.0E-6"^^xsd:double ; wikibase:geoGlobe <http://www.wikidata.org/entity/Q2> .
-
open_withSPARQL Update query for cleaning up missing values
DELETE { ?tree p:P625 ?s_625 . ?s_625 a wikibase:Statement, fromSource: ; #P625 - coordinate location psv:P625 ?v_625 ; prov:wasDerivedFrom ?ref_s_625 . ?ref_s_625 a wikibase:Reference, fromSource: ; #P248 - stated in pr:P248 drúsop: . ?v_625 a wikibase:GlobecoordinateValue ; wikibase:geoPrecision "1.0E-6"^^xsd:double ; wikibase:geoGlobe <http://www.wikidata.org/entity/Q2> . } WHERE { ?tree a wikibase:Item, fromSource: ; p:P625 ?s_625 . ?s_625 a wikibase:Statement, fromSource: ; #P625 - coordinate location psv:P625 ?v_625 ; prov:wasDerivedFrom ?ref_s_625 . ?ref_s_625 a wikibase:Reference, fromSource: ; #P248 - stated in pr:P248 drúsop: . ?v_625 a wikibase:GlobecoordinateValue ; wikibase:geoPrecision "1.0E-6"^^xsd:double ; wikibase:geoGlobe <http://www.wikidata.org/entity/Q2> . FILTER NOT EXISTS { ?v_625 wikibase:geoLatitude ?lat_double ; wikibase:geoLongitude ?lon_double ; } }
Wikidata Query Service lag
When running a Wikidata loading pipeline multiple times, one has to be aware of the current Wikidata Query Service lag. This is the time required for the updates done to the Wikibase instance to be propagated to the Blazegraph triplestores on top of which the Wikidata Query Service is running. It may happen that, for example, an Item is created in the Wikibase, but it is not yet propagated to the Blazegraph instance. When a pipeline runs and queries the Wikidata Query Service, the Item is still missing there, even though it has already been created in the Wikibase. This would lead to the creation of duplicates. Therefore, the current maximum lag should be respected as the minimum time interval between making updates to Wikidata and querying the Wikidata Query Service for the updates.
It may also happen, that the Wikibase and Wikidata Query Service are so overloaded, they stop accepting requests from bots completely. This can be then seen in the logs of the Wikibase loader like this:
2019-11-20 23:32:01,641 [pool-6-thread-1] INFO o.w.w.w.WbEditingAction - We are editing too fast. Pausing for 1396 milliseconds.
2019-11-20 23:32:03,258 [pool-6-thread-1] WARN o.w.w.w.WbEditingAction - [maxlag] Waiting for all: 5.2166666666667 seconds lagged. -- pausing for 5 seconds.
2019-11-20 23:32:08,499 [pool-6-thread-1] WARN o.w.w.w.WbEditingAction - [maxlag] Waiting for all: 5.2166666666667 seconds lagged. -- pausing for 5 seconds.
2019-11-20 23:32:13,707 [pool-6-thread-1] WARN o.w.w.w.WbEditingAction - [maxlag] Waiting for all: 5.2166666666667 seconds lagged. -- pausing for 5 seconds.
2019-11-20 23:32:19,177 [pool-6-thread-1] WARN o.w.w.w.WbEditingAction - [maxlag] Waiting for all: 5.2166666666667 seconds lagged. -- pausing for 5 seconds.
2019-11-20 23:32:24,411 [pool-6-thread-1] WARN o.w.w.w.WbEditingAction - [maxlag] Waiting for all: 5.2166666666667 seconds lagged. -- pausing for 5 seconds.
2019-11-20 23:32:29,412 [pool-6-thread-1] ERROR o.w.w.w.WbEditingAction - Gave up after several retries.
Last error was: org.wikidata.wdtk.wikibaseapi.apierrors.MaxlagErrorException:
[maxlag] Waiting for all: 5.2166666666667 seconds lagged.
In that case, the loader will wait until the lag has disappeared.
Use cases
Using the same method, these use cases were addressed:
- Veteran trees, groves and alleys from the Digital Register of the Nature Conservancy Central Register
- Task approval
- Pipeline for solitary trees (presented in this tutorial)
- Pipeline for groves and alleys
- Czech streets from the Register of territorial identification, addresses and real estates
- Task approval
- Pipeline
- Linking languages in Wikidata to languages in Language EU Vocabulary
- Task approval
- Pipeline
- Updating basic information about Czech theatres from the Virtual Study of the Theatre Institute
- Task approval
- Pipeline