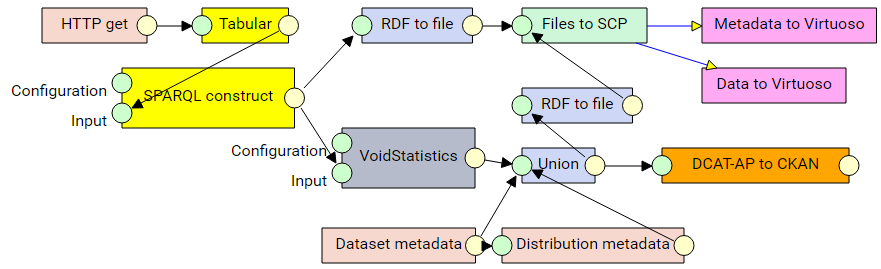
Experiment setup for ODBASE 2017
This page describes the steps necessary to reproduce the results described in our ODBASE 2017 paper submission.
LinkedPipes ETL can be installed using the installation guide. The experiments were performed using GitHub commit 4650115, but should work with further versions as well.
Once installed, the instance can be populated with the prepared pipelines by importing them from their IRIs listed for each dataset.
The memory available to the Java process of the executor module can be set in the script for running the component using the -Xmx2G parameter (example for 2 GB).
For the experimental pipelines, the input data needs to be downloaded to the machine running the LP-ETL instance and the initial Files from local components must point to it.
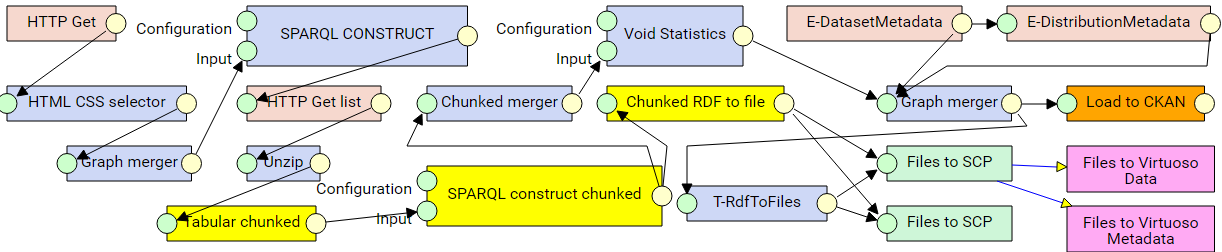
ARES

- Experimental pipeline
- Experimental input data needs to be unzipped.
- Full pipeline
- Full pipeline input data
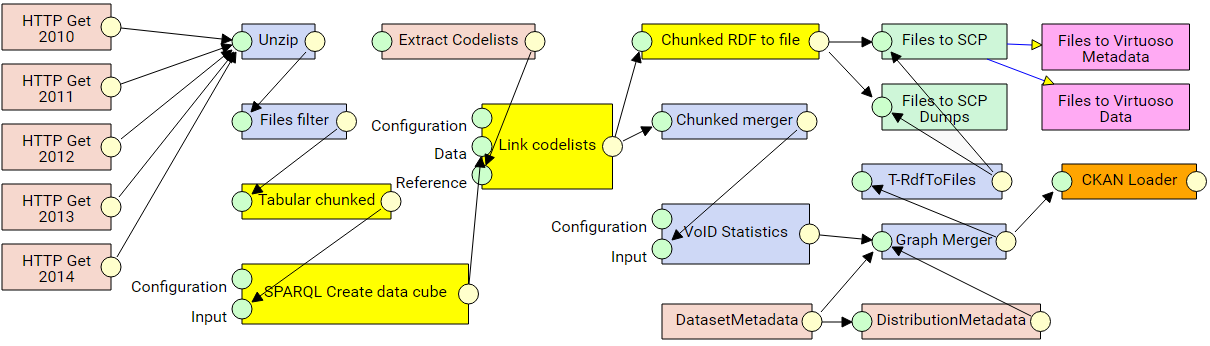
RÚIAN

- Experimental pipeline
- Experimental input data needs to be unzipped.
- Full pipeline

- Geocoding pipeline is dependent on our SPARQL endpoint.