Converting tabular data to RDF: Clean data
-
open_withSample RDF input
@prefix : <http://example.com/> . [ :AREA "1056740000" ; :CHANGE "no" ; :LAU1_NAT_CODE "146" ; :LAU2_NAT_CODE "005" ; :NAME_1 "Alajärvi" ; :NAME_2_LAT "Alajärvi" ; :NUTS_3 "FI194" ; :POP "10006" ; :sheet_name "FI" ] . [ :AREA "630200000" ; :CHANGE "no" ; :LAU1_NAT_CODE "041" ; :LAU2_NAT_CODE "050" ; :NAME_1 "Eura" ; :NAME_2_LAT "Eura" ; :NUTS_3 "FI196" ; :POP "12128" ; :sheet_name "FI" ] . [ :AREA "495420000" ; :CHANGE "no" ; :LAU1_NAT_CODE "131" ; :LAU2_NAT_CODE "592" ; :NAME_1 "Petäjävesi" ; :NAME_2_LAT "Petäjävesi" ; :NUTS_3 "FI193" ; :POP "4008" ; :sheet_name "FI" ] .
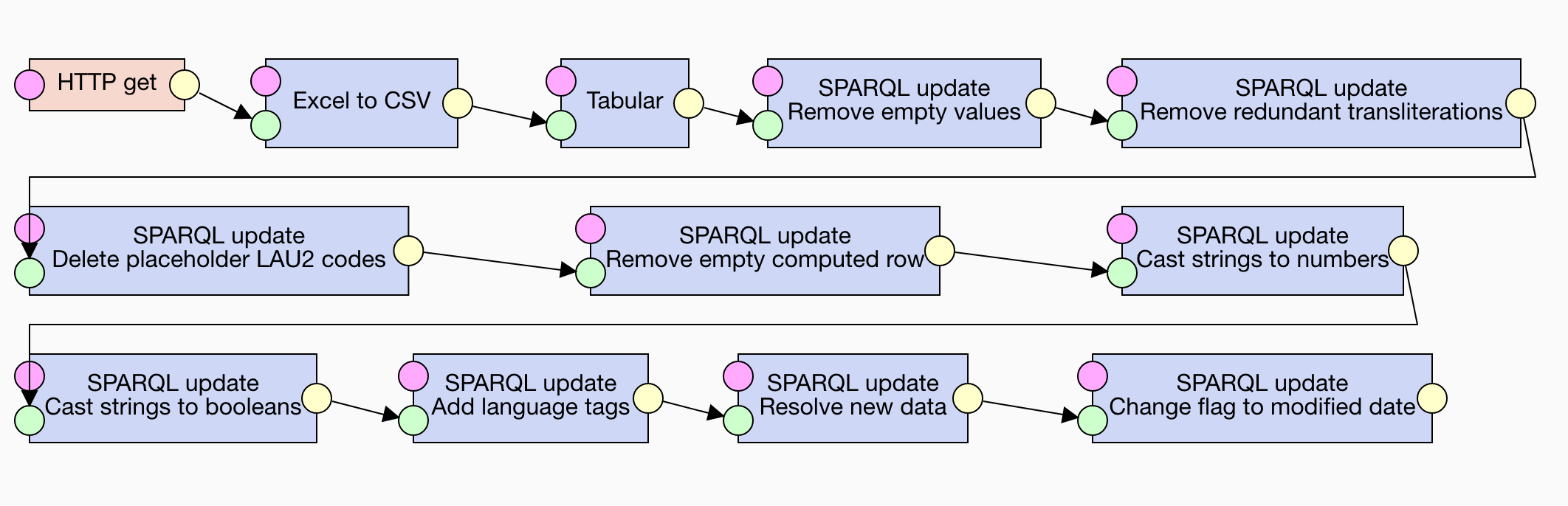
Now we have a syntactically valid RDF data. However, it has some imperfections that we can remedy. To clean the data we pipe it into the SPARQL Update component that allows us to run SPARQL 1.1 Update operations on the input RDF data. A handy assistant in developing SPARQL Update operations is the SPARQLer Update Validator that you can use to check the syntax of your update operations before entering them into LP-ETL. Cleaning and mapping data usually takes multiple steps, embodied by multiple instances of the SPARQL Update component. It is therefore useful to add a description to each instance to be able to differentiate them quickly. You can add a description to any component by going to its General tab and filling in the Description field.
We start with updates that delete data. Doing so speeds up subsequent transformations since they can operate on smaller data. First, we remove the empty values that are indicated with the placeholder "n.a.", or "n.a" alternatively:
PREFIX : <http://example.com/>
DELETE {
?s ?p ?o .
}
WHERE {
VALUES ?o {
"n.a"
"n.a."
}
?s ?p ?o .
}We also remove the redundant transliterations of the names of local administrative units.
The :NAME_2_LAT property provides Latin transliterations of the names.
Transliterations are useful for non-Latin names, such as in Cyrillic.
However, they provide no additional value if they are the same as the original names.
PREFIX : <http://example.com/>
DELETE {
?lau :NAME_2_LAT ?name .
}
WHERE {
?lau :NAME_1 ?name ;
:NAME_2_LAT ?name .
}Some local administrative units on the level 2 lack codes.
Instead, they are given a placeholder code 9999.
We delete these placeholder codes using the DELETE WHERE shorthand.
PREFIX : <http://example.com/>
DELETE WHERE {
?lau2 :LAU2_NAT_CODE "9999" .
}This SPARQL Update operation is equivalent to this longer form:
PREFIX : <http://example.com/>
DELETE {
?lau2 :LAU2_NAT_CODE "9999" .
}
WHERE {
?lau2 :LAU2_NAT_CODE "9999" .
}Due to a superfluous formula in the source spreadsheet, the generated RDF contains a corresponding empty row for which the formula computes its area to be zero.
In order to remove this row, we match the rows that have only the properties :sheet_name and :AREA and delete them.
PREFIX : <http://example.com/>
DELETE {
?row ?p ?o .
}
WHERE {
?row :sheet_name [] .
# The row does not have any other property besides :sheet_name and :AREA.
FILTER NOT EXISTS {
?row !(:sheet_name|:AREA) [] .
}
?row ?p ?o .
}By default, Tabular outputs all literals as strings.
Besides strings, our dataset contains numbers and boolean values, so we cast these values to their suitable data types.
We cast the values of the properties :AREA and :POP to integers:
PREFIX : <http://example.com/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
DELETE {
?s ?p ?string .
}
INSERT {
?s ?p ?number .
}
WHERE {
VALUES ?p {
:AREA
:POP
}
?s ?p ?string .
BIND (strdt(?string, xsd:integer) AS ?number)
}Yes/no values are mapped to boolean true/false:
PREFIX : <http://example.com/>
DELETE {
?s :CHANGE ?string .
}
INSERT {
?s :CHANGE ?boolean .
}
WHERE {
VALUES (?string ?boolean) {
("yes" true)
("no" false)
}
?s :CHANGE ?string .
}Finally, we infer language tags of the names based on countries where the local administrative units are located. We use a manually created lookup table to map country codes to ISO 639-1 language codes.
PREFIX : <http://example.com/>
DELETE {
?lau :NAME_1 ?_name .
}
INSERT {
?lau :NAME_1 ?name .
}
WHERE {
VALUES (?country ?language) {
("AT" "de")
("BE" "be")
("BG" "bg")
("CY" "el")
("CZ" "cs")
("DE" "de")
("DK" "da")
("EE" "et")
("EL" "el")
("ES" "es")
("FI" "fi")
("FR" "fr")
("HR" "hr")
("IE" "en")
("IT" "it")
("LT" "lt")
("LU" "lb")
("LV" "lv")
("MT" "mt")
("NL" "nl")
("PL" "pl")
("PT" "pt")
("RO" "ro")
("SE" "sv")
("SI" "sl")
("SK" "sk")
("UK" "en")
}
?lau :NAME_1 ?_name ;
:sheet_name ?country .
BIND (strlang(?_name, ?language) AS ?name)
}Note that the mapping between countries and languages is a simplification, because there are EU member countries that have multiple official languages, such as Ireland where both Irish and English are spoken. Consequently, there is a chance that this mapping assigns the names of local administrative units with incorrect language tags.
-
open_withSample RDF output
@prefix : <http://example.com/> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . [ :AREA "1056740000"^^xsd:decimal ; :CHANGE false ; :LAU1_NAT_CODE "146" ; :LAU2_NAT_CODE "005" ; :NAME_1 "Alajärvi"@fi ; :NUTS_3 "FI194" ; :POP 10006 ; :sheet_name "FI" ] . [ :AREA "630200000"^^xsd:decimal ; :CHANGE false ; :LAU1_NAT_CODE "041" ; :LAU2_NAT_CODE "050" ; :NAME_1 "Eura"@fi ; :NUTS_3 "FI196" ; :POP 12128 ; :sheet_name "FI" ] . [ :AREA "495420000"^^xsd:decimal ; :CHANGE false ; :LAU1_NAT_CODE "131" ; :LAU2_NAT_CODE "592" ; :NAME_1 "Petäjävesi"@fi ; :NUTS_3 "FI193" ; :POP 4008 ; :sheet_name "FI" ] .