Converting tabular data to RDF: Optimize
If we run our pipeline, we can notice that its full execution may take around 100 minutes to complete. The runtime can vary significantly based on network latency or the specification of the computer that you run the pipeline on. This speed may be fine for our dataset, since it changes only once a year, but LP-ETL can do better. Faster execution also benefits the pipeline development cycle, since we can iterate more quickly if the pipeline's results are produced without much delay. There are several ways how we can improve the runtime of our pipeline.
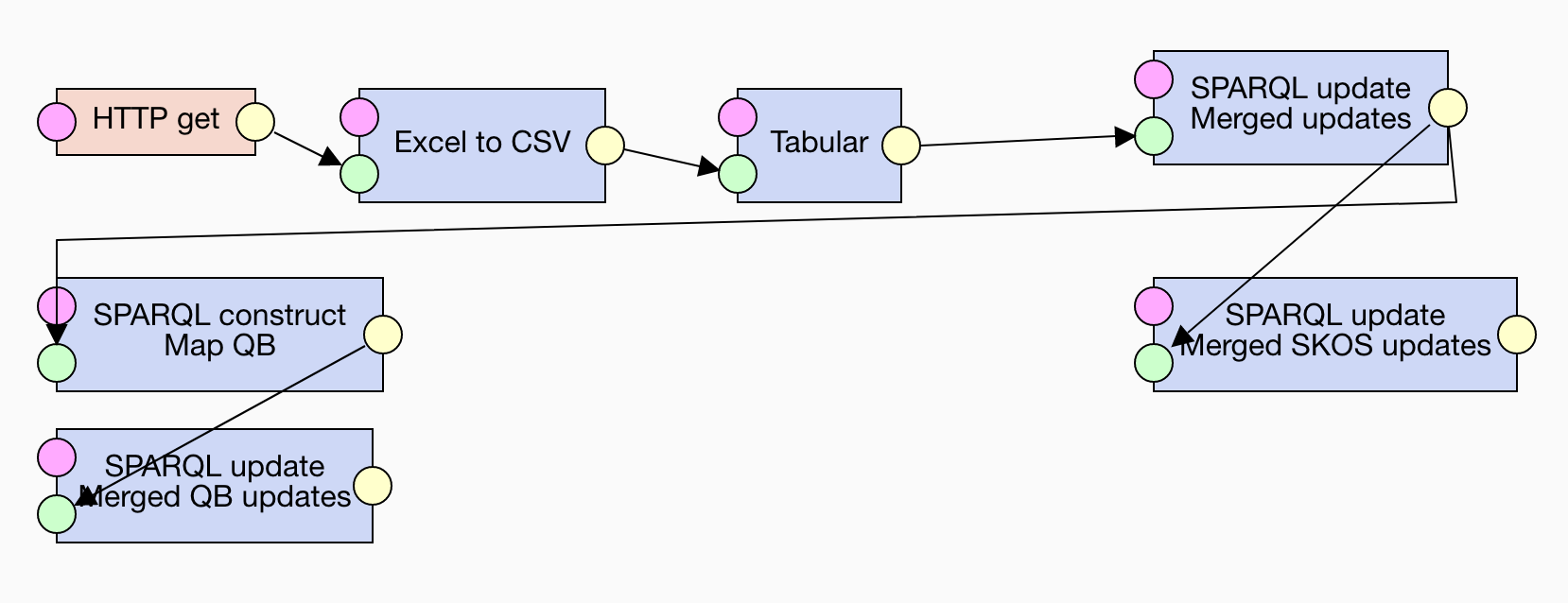
LP-ETL materializes the output of each processing step. While having the intermediate data is useful for debugging, it slows down the pipeline execution since LP-ETL has to serialize the data to files. We can avoid some of this overhead by merging SPARQL Update operations. SPARQL Update allows to combine multiple operations into a single request that is executed in one go. Multiple operations can be concatenated together if separated by semicolons. The operations are executed sequentially in the order they appear in the combined request, so that results of each operation are available to the operations that follow it. This allows us to merge subsequent operations that operate on the same data. We can therefore combine the initial updates and then the updates operating on the two branches of our pipeline. Doing so can speed up the pipeline approximately to half of its original runtime.
The example pipeline using this improvement can be found here.
We can also improve the pipeline's runtime by letting it operate on smaller chunks of RDF. LP-ETL loads RDF into an in-memory store and larger data in bulk can take longer to process than the same data split into smaller parts. In order to leverage this optimization, LP-ETL provides special versions of many of its components that can operate on collections of chunks of RDF data. To split data into chunks, which are then processed separately, we can use Tabular chunked and then transform it via SPARQL Update chunked or SPARQL CONSTRUCT chunked. Tabular chunked allows to specify the size of the individual chunks in terms of the number of rows of its input CSV. Note that the chunked execution may be applied only to transformations that make do with the data present in one chunk. Transformations that require data outside of each chunk, such as the whole dataset, cannot be executed on chunks. For example, this mode of execution cannot be applied to deduplication that requires joins across the whole dataset. Also note that chunking carries an overhead of needing to merge the chunked data via the Chunked merger component at the end. It should be therefore employed only for demanding transformations, in which the time savings gained from chunked execution trump the overhead with merging data.
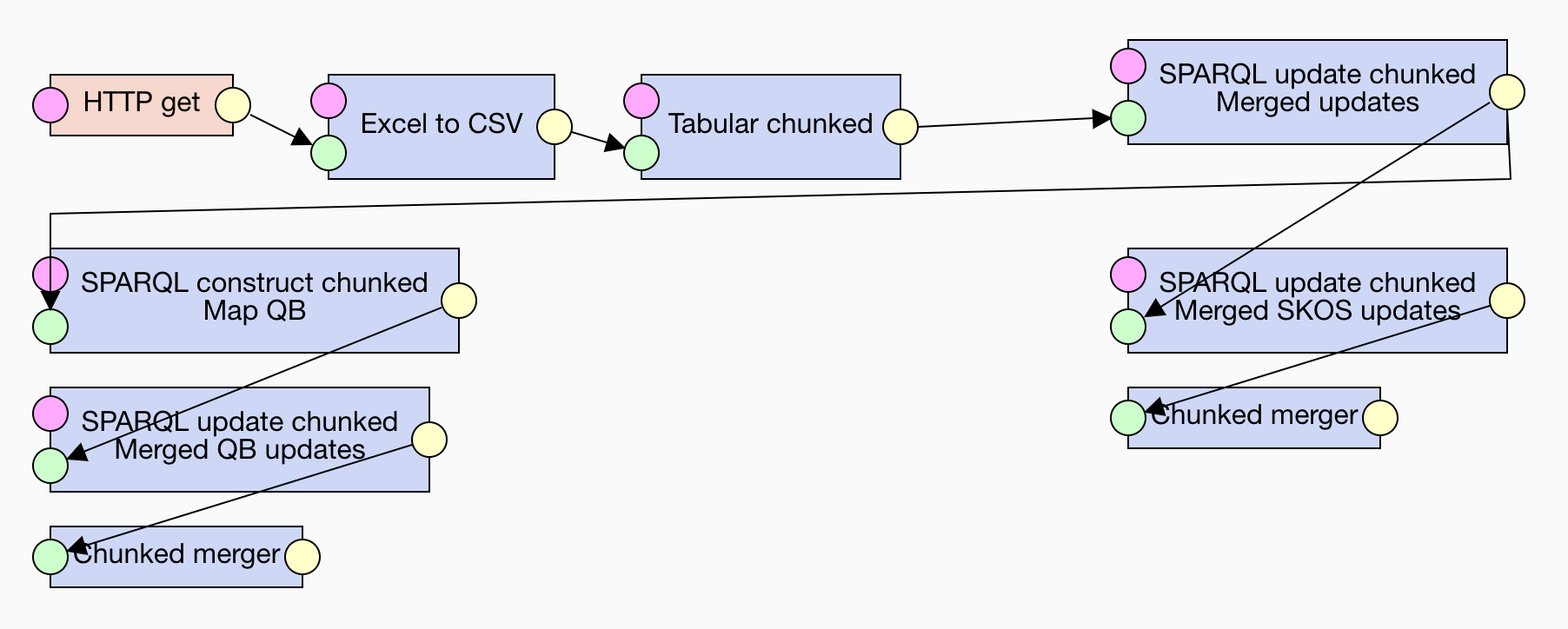
You can see how this optimization changes the runtime of the individual transformations. In the execution view, you can click on the components to see how long their execution took. For example, while the merged initial update takes around 40 minutes to execute, its chunked version is roughly 10 times faster. Using this feature also allows you to detect bottlenecks that slow your pipeline down. Overall, when we the employ chunked execution the pipeline execution speed improves to around a fourth of the runtime of the previous version with merged updates. As you can see, the speed-up granted by these optimizations is significant, since the pipeline that originally took around 100 minutes to run takes roughly 13 minutes when optimized.
A final option for optimization lies in executing pipelines without debug data. This execution mode can be triggered from the pipeline view using the top-right menu. If you run pipeline in this mode, then no intermediate data produced by the pipeline's components are kept, which saves time and reduces the disk space used by the execution. This mode is suitable for stable pipelines that are already debugged. During pipeline development, you probably want to execute pipelines in the standard mode that retains intermediate data for further debugging.
You can find the optimized version of the example pipeline here.