How to convert CSV to RDF
You want to combine Comma-Separated Values (CSV) files with RDF data.
Problem
There are many reasons for converting CSV to RDF, but the most common one likely is wanting to combine CSV data with other data. RDF offers a straightforward way to combine multiple datasets. RDF datasets can be merged automatically as set union of their triples or quads. You can also deepen the integration by using common RDF vocabularies to describe the combined datasets in a semantic fashion. Once merged, RDF allows you to run expressive queries over the combined data.
Consider, for example the CSV version of the list of media types registered by IANA. This dataset lends itself to a number of uses, such as inferring media type from the extensions of files linked from RDF data. This is how the data is structured:
| Media Type | Type | Subtype | Template | Extensions |
|---|---|---|---|---|
| text/css | text | css | http://www.iana.org/assignments/media-types/text/css | css |
| text/csv | text | csv | http://www.iana.org/assignments/media-types/text/csv | csv |
| text/csv-schema | text | csv-schema | http://www.iana.org/assignments/media-types/text/csv-schema |
Solution
Converting CSV to RDF is a task so common that numerous solutions were devised to address it. LinkedPipes ETL (LP-ETL) offers the Tabular component for this task. It performs a syntactic transformation of CSV to RDF that follows the W3C recommendation Generating RDF from Tabular Data on the Web. Simply put, it turns rows from a CSV file into RDF resources described by RDF properties derived from the file's column headers. Here is an output of the Tabular component for the CSV fragment shown above using the default settings of the component. The output is shown in a prettified Turtle syntax for RDF:
@base <file://media-types.csv#> .
[ <Media+Type> "text/css" ;
<Subtype> "css" ;
<Template> "http://www.iana.org/assignments/media-types/text/css" ;
<Type> "text" ;
<Extensions> "css" ] .
[ <Media+Type> "text/csv" ;
<Subtype> "csv" ;
<Template> "http://www.iana.org/assignments/media-types/text/csv" ;
<Type> "text" ;
<Extensions> "csv" ] .
[ <Media+Type> "text/csv-schema" ;
<Subtype> "csv-schema" ;
<Template> "http://www.iana.org/assignments/media-types/text/csv-schema" ;
<Type> "text" ] .The pipeline that implements this conversion is here. You can experiment with the settings of the Tabular component in this pipeline, run it, and examine its output.
Let's review the configuration options of this component. The component exposes quite a few options to customize how it handles its input as well as how its output should look like.
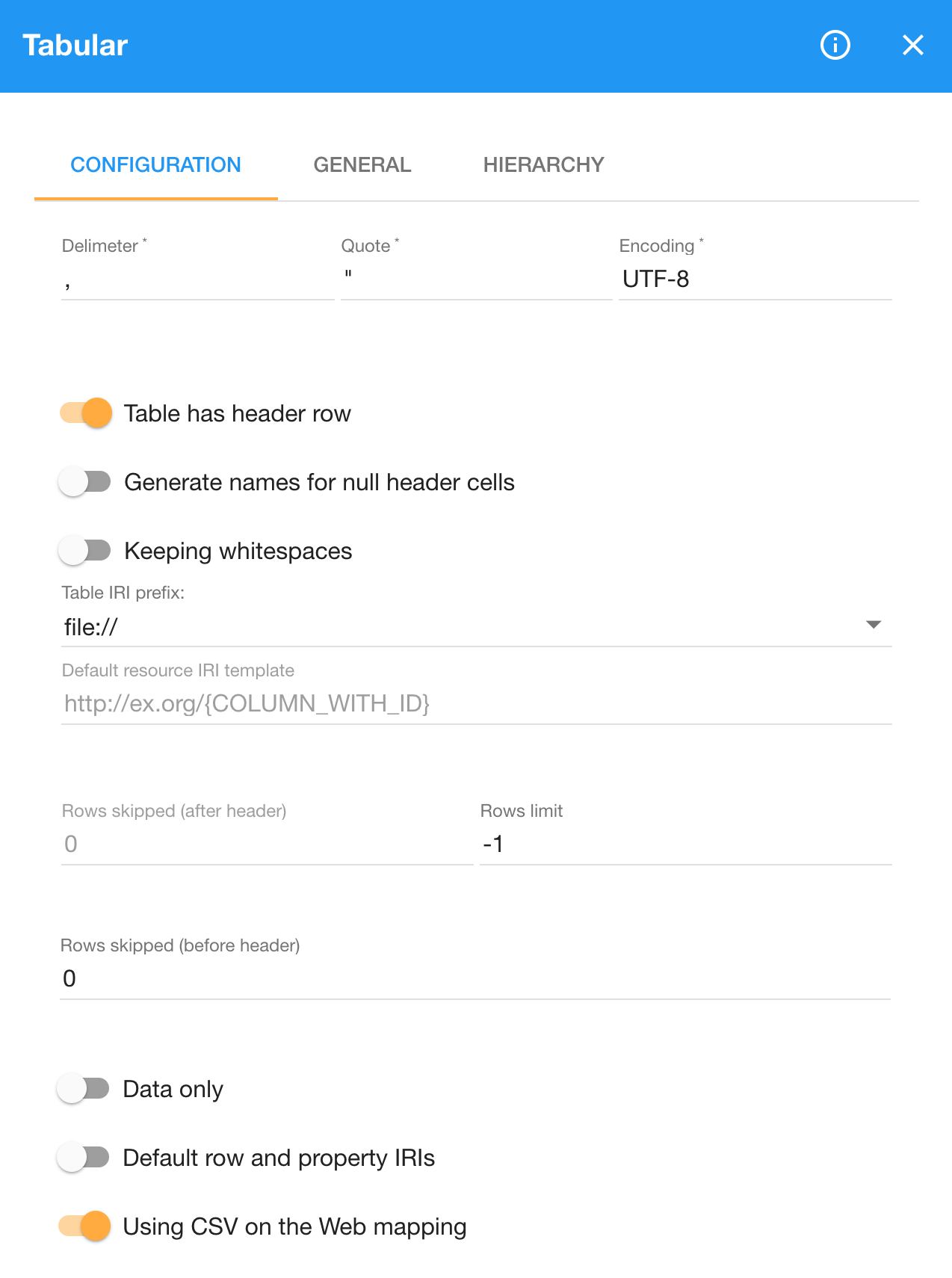
The first section of the configuration enables to handle input data that does not conform to the RFC 4180, which specifies the default syntax of CSV files. As the name describes, data in CSV files is separated by commas. However, it is common to have data separated by other characters, such as Tab-separated values. Similarly, languages that use comma as decimal separator often employ semicolon to delimit data in CSV. You can configure any character to act as the separator via the Delimiter option. However, note that the tabulator for TSV must be escaped as \t. Besides the separator, you can also specify the quote character, which is " by default, and the input's character encoding, defaulting to UTF-8.
The IRIs of RDF properties that the Tabular component produces are derived from the input's column headers. For instance, when the input has a column named Type, the component turns it into an IRI ending with Type. Characters from the column names that are not allowed in IRIs, such as whitespace, are replaced by safe characters. For example, spaces are substituted by plus signs. The initial part of the IRIs is determined by options we discuss further. Column names are used when the switch Table has header row is on. Otherwise, when there are no column names in the input, you can turn this option off. In such case, the generated RDF properties will end with column_1, column_2, and so on.
When the Table has header row option is switched on and some columns are missing names, the Tabular component fails, since it cannot use an empty name for an IRI of an RDF property. To work around this, you need to turn on the option Generate names for null header cells. It makes LP-ETL generate synthetic names for the empty header cells, such as generated_name_1, generated_name_2 etc.
You can trim leading or trailing whitespace from the input data by switching on the option Trim whitespace from cells. The option is off by default, keeping the whitespace characters in the input.
Namespaces of IRIs identifying the RDF properties generated by the component are determined by two options. By default, the IRIs start with the name of the input file using the file:// protocol. For example, if the input file name is data.csv, the IRI for the column Media type will be file:///data.csv#Media+type. Originally, the component generated invalid IRIs missing the forward slash separating its hostname from its path, such as file://data.csv#Media+type. To preserve backwards compatibility the option Table IRI prefix was added, which defaults to the incorrect file:// prefix and allows you to opt in for the correct file:/// prefix.
Alternatively, you can provide a fixed namespace for the generated IRIs to be used instead of the input file names. In order to do that, you need to switch the Default row and property IRIs option to Specified row and property IRI base, which in turn allows you to specify the Row and property IRI base. For example, we used the fixed namespace http://localhost/ in our example above. Setting a static namespace is handy especially when you have multiple input files in which the same column names have the same interpretation, so that they are transformed to the same RDF properties instead of ones differing by file names.
The output RDF resources corresponding to rows from the input CSV are identified by blank nodes by default. Alternatively, the resources can be identified by IRIs generated from a template provided as Default resource IRI template. Syntax of the template is defined by RFC 6570. The templates allow you to refer to column values via column names. For instance, the template http://example.com/{ID} would put values of the ID column in place of the {ID} reference. Using IRI templates is convenient when your source data contains a unique key for each row. Otherwise, you may want to stick with blank nodes as identifiers and generate IRIs based on more complex rules expressed in SPARQL during post-processing of the Tabular's output.
Since CSV files may wrap the actual data with irrelevant rows, such as with a preamble containing notes, the Tabular component enables you to specify rows to be ignored. You can have it skip the rows prior to the header via the Rows skipped (before header) option. Rows after the header can be skipped too, using the Rows skipped (after header) option. You can also discard the final rows by specifying the Rows limit option, which determines how many rows after the header are processed. By default, it has the value -1 that indicates no limit. You may find setting a smaller number of rows useful during pipeline development. Working with a small data sample is fast and allows an easy visual inspection to verify that the pipeline does what it is expected to do.
The Tabular component implements the W3C recommendation Generating RDF from Tabular Data on the Web. The option Using CSV on the Web mapping, turned on by default, instructs the component to follow this recommendation. The recommendation specifies how to map CSV to RDF. It defines two modes of conversion. The minimal mode includes only the data from the cells of the transformed CSV. The standard mode also outputs RDF describing the structure of the transformed CSV, including details of rows, tables, and table groups. The minimal mode is the default mode in the Tabular component, as indicated by the switch Data only. Should you want the structure of the input CSV to be explicitly described in RDF, flip this switch to the state Table and row entities.
You can provide a custom mapping from CSV to RDF if you switch the option Using CSV on the Web mapping off to Using custom mapping. Custom mapping is included mostly to maintain compatibility with the previous versions of the Tabular component. More often than not, you will map the Tabular's default output in the subsequent steps of your pipeline that allow you to formulate more expressive mappings, such as those using SPARQL Update. However, there are cases in which the custom mapping is indispensable. When you transform large CSV data containing many irrelevant columns, they too are converted to RDF when using the standard mapping. On contrary, the custom mapping allows you to mark columns to be discarded, so that no RDF is created from them. Doing so reduces the use of compute resources that would be required for data subsequently discarded in a pipeline.
Discussion
Large CSV files present an opportunity for parallelization, since their rows are typically independent, so that they can be processed separately. LP-ETL enables you to leverage this opportunity via the Tabular chunked component. It splits its input data into smaller chunks that are processed separately and in parallel. The size of each chunk is determined by the number of included rows via the Rows per chunk option. Apart from this option, the component's configuration is identical with that of the Tabular component. The component produces a sequence of RDF chunks that can be further processed by components that support chunked execution, as described in the tutorial on handling large RDF data.
See also
Conversion of CSV to RDF is discussed in a larger context in the tutorial on converting tabular data to RDF. There you can see how the Tabular component can fit into a more extensive pipeline.