Converting tabular data to RDF: Add metadata
In our final step, we annotate the produced data with metadata. LP-ETL supports describing the processed datasets using metadata expressed using the standard Data Catalog Vocabulary (DCAT). In particular, it uses the DCAT application profile for data portals in Europe (DCAT-AP). Datasets can be described by the DCAT-AP Dataset component and their distributions can be covered by the DCAT-AP Distribution component. In this context, distributions correspond to specific forms of a given dataset, such as downloadable files or APIs.
Both components provide expressive means to characterize datasets using descriptive, structural, and administrative metadata in RDF. The mandatory metadata required for a DCAT-AP dataset are grouped in the initial section of the component. The remaining sections enable you to fill in other recommended or optional metadata. In case of the statistical data cube, you can also provide metadata using the StatDCAT-AP extension of DCAT-AP. For the data described by QB, the StatDCAT-AP metadata overlaps with the dataset's DSD, since it too lists the attributes and dimensions used in the dataset. The metadata produced by the DCAT-AP Dataset component can be fed into the DCAT-AP Distribution component instead of filling in the links between a distribution and its dataset manually. If you loaded a data dump to a directory exposed via an HTTP server, as suggested previously, you can fill in the server's host name with the path to the dump as the download URL of the distribution.
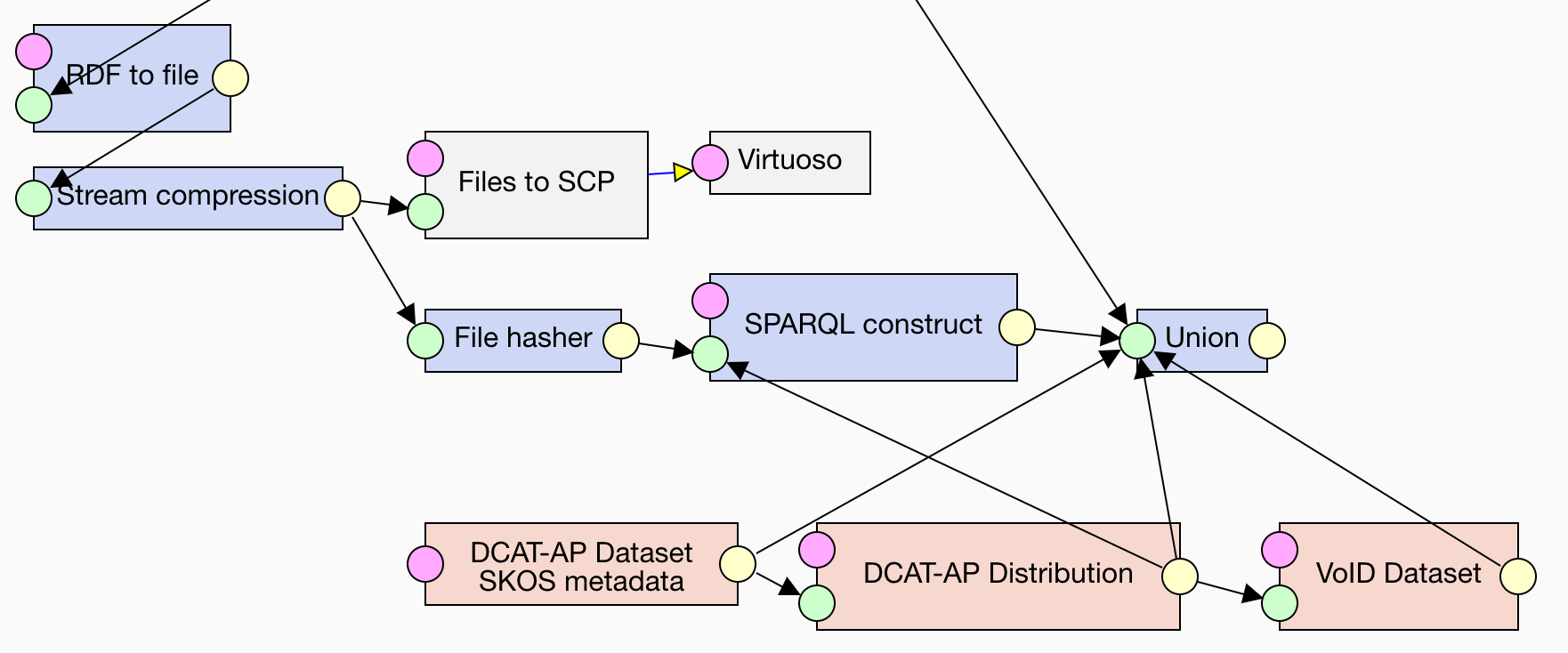
Apart from DCAT-AP, LP-ETL supports the Vocabulary of Interlinked Datasets (VoID) via the VoID Dataset component.
In terms of VoID the void:Dataset matches the dcat:Distribution.
You can thus feed the output of the DCAT-AP Distribution component to VoID Dataset that uses it to produce metadata in VoID.
In this component you can also specify the IRI of an example resource and the URL of the SPARQL endpoint exposing the dataset.
Since metadata is just RDF, many other LP-ETL components can be employed to generate it. Besides DCAT-AP, you can provide static metadata described by any other vocabulary via the Text holder component. Should you need to generate dynamic metadata derived from your data, you can pipe the data into a SPARQL CONSTRUCT component with a query that computes the metadata. In the example pipeline, we use this approach to create metadata described in VoID. By using a CONSTRUCT query we compute statistics about the processed data, such as the count of triples or the number of distinct instantiated classes:
PREFIX void: <http://rdfs.org/ns/void#>
CONSTRUCT {
<https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016/distribution> a void:Dataset;
void:triples ?triples ;
void:entities ?entities ;
void:classes ?classes ;
void:properties ?properties ;
void:distinctSubjects ?subjects ;
void:distinctObjects ?objects .
}
WHERE {
{
SELECT (COUNT(*) AS ?triples)
(COUNT(DISTINCT ?p) AS ?properties)
(COUNT(DISTINCT ?s) AS ?subjects)
(COUNT(DISTINCT ?o) AS ?objects)
WHERE {
?s ?p ?o .
}
}
{
SELECT (COUNT(DISTINCT ?s) AS ?entities)
(COUNT(DISTINCT ?class) AS ?classes)
WHERE {
?s a ?class .
}
}
}To enable verification of integrity of the downloaded data distributions, you can provide a hash of the distribution files as part of their metadata. When a file is downloaded, its integrity can be verified by computing its hash and comparing it with the hash in the metadata. The File hasher component computes an SHA-1 hash of its input. To include its output in the metadata we combine it with the distribution metadata by using the following CONSTRUCT query:
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX fh: <http://plugins.linkedpipes.com/ontology/t-filehash#>
PREFIX spdx: <http://spdx.org/rdf/terms#>
CONSTRUCT {
?distribution spdx:checksum ?checksumIRI .
?checksumIRI a spdx:Checksum ;
spdx:algorithm ?algorithm ;
spdx:checksumValue ?value.
}
WHERE {
?distribution a dcat:Distribution .
[] spdx:checksum ?checksum .
?checksum a spdx:Checksum ;
spdx:algorithm ?algorithm ;
spdx:checksumValue ?value .
BIND (iri(concat(str(?distribution), "/checksum")) AS ?checksumIRI)
}To merge multiple metadata outputs you can use the Union component, which combines several RDF inputs into a single output. We persist the merged metadata using the above-described loaders, producing both a file dump and loading the data to an RDF store.
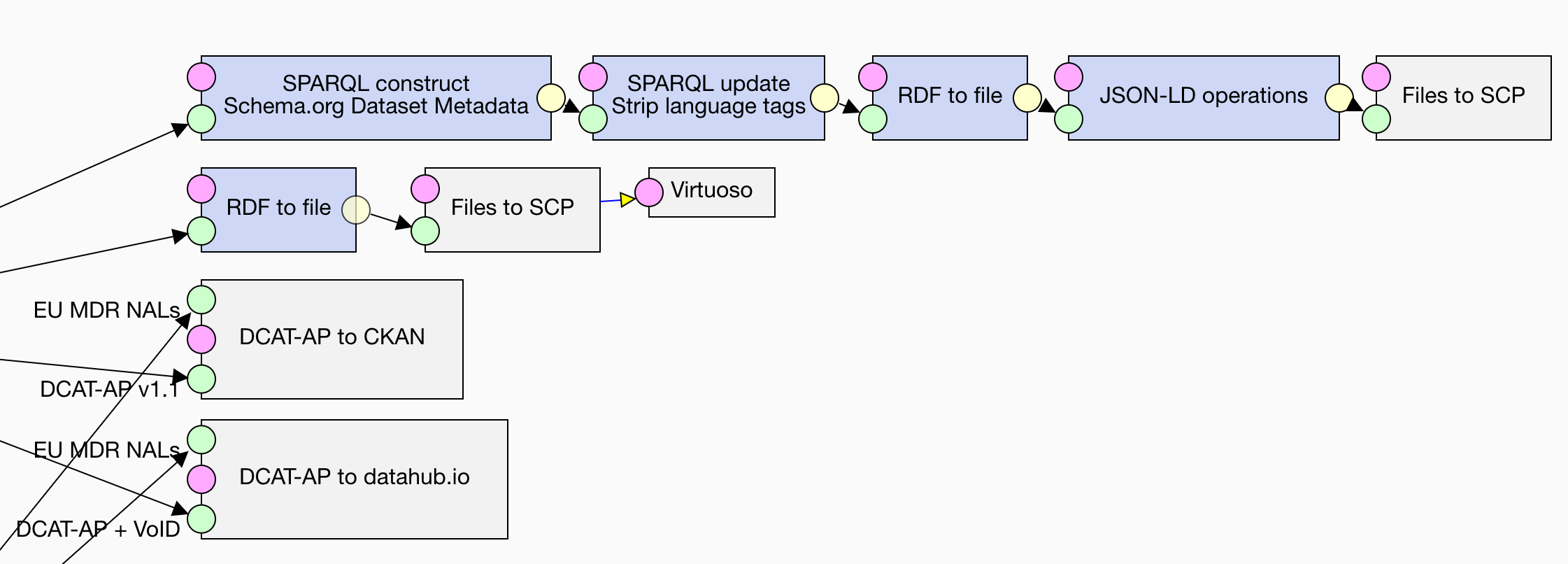
To make the data easier to discover and present in search engines we can generate Schema.org dataset metadata.
A dataset can be described as an instance of schema:Dataset using the properties declared by the Schema.org vocabulary.
The data model for dataset metadata already matches well with DCAT, but there is also a Schema.org for datasets community group that works towards even better alignment and extension of Schema.org for datasets.
We generate the Schema.org metadata by transforming the DCAT-AP metadata via a CONSTRUCT query:
PREFIX dcat: <http://www.w3.org/ns/dcat#>
PREFIX dcterms: <http://purl.org/dc/terms/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX schema: <http://schema.org/>
CONSTRUCT {
?dataset a schema:Dataset;
schema:distribution ?distribution ;
schema:name ?title ;
schema:keywords ?keyword ;
schema:url ?lp ;
schema:description ?description ;
schema:creator ?publisher ;
schema:includedInDataCatalog ?catalog .
?distribution a schema:DataDownload ;
schema:contentUrl ?download ;
schema:fileFormat ?mediatype .
?publisher a schema:Organization;
schema:name ?pname .
?catalog a schema:DataCatalog;
schema:dataset ?dataset .
}
WHERE {
?dataset a dcat:Dataset;
dcterms:title ?title ;
dcat:distribution ?distribution .
OPTIONAL {
?dataset dcat:keyword ?keyword .
}
OPTIONAL {
?dataset dcterms:description ?description .
}
OPTIONAL {
?dataset dcat:landingPage ?landingPage .
BIND (str(?landingPage) AS ?lp)
}
?distribution a dcat:Distribution .
OPTIONAL {
?distribution dcat:downloadURL ?download .
}
OPTIONAL {
?distribution dcat:mediaType ?mediatype .
}
OPTIONAL {
?dataset dcterms:publisher ?publisher .
?publisher foaf:name ?pname .
}
OPTIONAL {
?catalog dcat:dataset ?dataset .
}
}Since the Google Structured Data Testing Tool currently does not support language tags, we remove them from the Schema.org metadata via a SPARQL Update operation:
DELETE {
?s ?p ?_literal .
}
INSERT {
?s ?p ?literal .
}
WHERE {
?s ?p ?_literal .
FILTER (isLiteral(?_literal) && lang(?_literal) != "")
BIND (str(?_literal) AS ?literal)
}We serialize the generated RDF into JSON-LD via the RDF to file component. JSON-LD is one of the formats for Schema.org metadata supported by search engines. To make the resulting JSON-LD terser, we can use the JSON-LD operations component that performs the operations defined in the JSON-LD API on its input. We simply invoke the compact operation on the input using the Schema.org context:
{
"@context": "http://schema.org/"
}The component then dereferences the context, asking for its representation in JSON-LD.
You can examine it yourself, for example by requesting it via the command-line tool curl with the Accept header indicating the JSON-LD MIME type (i.e. curl -LH "Accept:application/ld+json" http://schema.org).
The obtained context guides the structure and abbreviations of the JSON-LD data that is subject to compaction.
The resulting compact JSON-LD can be published on the Web, so that search engines can crawl it and incorporate its metadata in their indices.
An alternative path for making the data easy to discover is to publish its metadata in a data catalogue.
LP-ETL supports loading metadata to data catalogues based on CKAN, into which you can deliver your metadata via the DCAT-AP to CKAN component.
The component expects its input to be described using the DCAT-AP vocabulary, so that you can pipe in it the output of the DCAT-AP components.
The input data is combined with the component's configuration and transformed to JSON that conforms with the CKAN data model.
The component requires you to specify the API endpoint's URL of the CKAN instance to which you load metadata, such as http://ckan.net/api/3.
In order to authorize the component to store metadata in the given CKAN instance, you need to provide it with a CKAN API key.
You can find your API key when you log into the CKAN instance and navigate to your profile page.
To identify the loaded dataset in the data catalogue you must to give it a unique dataset ID.
While DCAT-AP allows you to express multilingual metadata, CKAN's data model is monolingual, so you need to select one of the languages in DCAT-AP metadata to use in the metadata for CKAN.
If you provide the component with VoID metadata as well, as is the case in our example pipeline, the component can generate CKAN resources from it.
The component requires one more input; and that is the code list of file types.
You can download its RDF dump via the HTTP GET component, convert it to RDF via the Files to RDF single graph and feed it into the DCAT-AP to CKAN component by connecting to its dedicated port.
LP-ETL also offers the DCAT-AP to datahub.io component that is tied to the CKAN instance at datahub.io. This data catalogue provides source data for the Linking Open Data cloud diagram (LOD cloud), so that you can use the component to publish data to become a part of this renowned diagram. The component mostly mirrors the DCAT-AP to CKAN component. In addition to the configuration we described for its parent component, you need to provide it with the ID of a CKAN organization that will own the uploaded dataset. Since CKAN uses specific IDs for dataset licences different from those in DCAT-AP, you should select the appropriate licence in the component's configuration. Moreover, you can provide metadata designated for the LOD cloud diagram, such as the dataset's topic or its links to other datasets already included in the LOD cloud. For example, we can describe that our dataset features 173 links to NUTS 2010 in RDF.
-
open_withSample metadata in RDF
@prefix adms: <http://www.w3.org/ns/adms#> . @prefix dcat: <http://www.w3.org/ns/dcat#> . @prefix dcterms: <http://purl.org/dc/terms/> . @prefix dimension: <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/statistics/dimension/> . @prefix owl: <http://www.w3.org/2002/07/owl#> . @prefix qb: <http://purl.org/linked-data/cube#> . @prefix qudt: <http://qudt.org/vocab/unit#> . @prefix sdmx-attribute: <http://purl.org/linked-data/sdmx/2009/attribute#> . @prefix sdmx-dimension: <http://purl.org/linked-data/sdmx/2009/dimension#> . @prefix spdx: <http://spdx.org/rdf/terms#> . @prefix statdcat: <http://data.europa.eu/(xyz)/statdcat-ap/> . @prefix void: <http://rdfs.org/ns/void#> . @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016/statistics> a dcat:Dataset ; dcterms:accessRights <http://publications.europa.eu/resource/authority/access-rights/PUBLIC> ; dcterms:accrualPeriodicity <http://publications.europa.eu/resource/authority/frequency/ANNUAL> ; dcterms:issued "2016-01-01"^^xsd:date ; dcterms:modified "2017-06-29"^^xsd:date ; dcterms:publisher <http://opendata.cz> ; dcterms:title "LAU 2016 statistics"@en ; dcterms:type <http://publications.europa.eu/resource/authority/dataset-type/STATISTICAL> ; owl:versionInfo "2016" ; adms:versionNotes "Version for the year 2016"@en ; dcat:contactPoint <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016/statistics/contactPoint> ; dcat:distribution <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016/statistics/distribution> ; dcat:keyword "European Union"@en, "geography"@en, "statistics"@en, "demography"@en ; dcat:theme <http://publications.europa.eu/resource/authority/data-theme/SOCI> ; statdcat:attribute sdmx-attribute:obsStatus ; statdcat:dimension qb:measureType , sdmx-dimension:refPeriod , dimension:refArea ; statdcat:statMeasure qudt:SquareMeter . <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016/statistics/distribution> a dcat:Distribution, void:Dataset ; dcterms:format <http://publications.europa.eu/resource/authority/file-type/RDF_TRIG> ; dcterms:issued "2016-01-01"^^xsd:date ; dcterms:modified "2017-06-29"^^xsd:date ; dcterms:title "Gzipovaný dump v RDF TriG"@cs , "Gzipped RDF TriG Dump"@en ; dcterms:type <http://publications.europa.eu/resource/authority/distribution-type/DOWNLOADABLE_FILE> ; adms:status <http://purl.org/adms/status/Completed> ; dcat:accessURL <https://linked.opendata.cz/dataset/lau-2016-statistics> ; dcat:downloadURL <https://obeu.vse.cz/dump/lau_2016_statistics.trig.gz> ; dcat:mediaType <http://www.iana.org/assignments/media-types/application/trig> ; spdx:checksum <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016/statistics/distribution/checksum> ; void:classes 7 ; void:dataDump <https://obeu.vse.cz/dump/lau_2016_statistics.trig.gz> ; void:distinctObjects 166440 ; void:distinctSubjects 176940 ; void:entities 175924 ; void:exampleResource <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/observation/cz/554782/2016/populationTotal> ; void:properties 21 ; void:sparqlEndpoint <http://obeu.vse.cz:8890/sparql> ; void:triples 1090105 . <https://linked.opendata.cz/resource/ec.europa.eu/eurostat/lau/2016/statistics/distribution/checksum> a spdx:Checksum ; spdx:algorithm spdx:checksumAlgorithm_sha1 ; spdx:checksumValue "1d89b35e6e1f1a08b93a02c6c954e3e4ad97e125"^^xsd:hexBinary .
The final version of our example pipeline that includes the metadata is available here. The interdependencies between the metadata components make the pipeline impossible to layout without edge crossings, but you can achieve a reasonably clear layout as we tried in the example pipeline.
Summary
We covered a lot of ground in this tutorial. You learnt about the steps involved in producing linked data in RDF out of tabular data. LP-ETL provides an extensive toolbox of components that can automate these steps. We illustrated the use of LP-ETL components on an example dataset of Local Administrative Units. The example allowed us to showcase how to deal with Excel spreadsheets with multiple sheets, convert CSV to RDF, implement data cleaning rules, express data using RDF vocabularies, link data, optimize the performance of the transformation pipeline, store the output data, and finally describe it with metadata. If you want delve into more depth on LP-ETL, you may go through its documentation or the documentation of its individual components.