How to cache linked data
Your data references linked data resources. You want to cache their data locally.
Problem
Linked data is a publication model for data distributed on the Web. If you look at the famous Linking Open Data cloud diagram, you can see hundreds of linked datasets distributed on many servers. While there are tasks that can be solved by traversing the distributed linked data, other tasks call for collecting the required data locally. For example, storing linked data in a local cache is expedient if the data is accessed frequently and must be available quickly.
Solution
According to the best practice embodied by the linked data principles, IRIs of linked data resources can be dereferenced to obtain their descriptions. Servers exposing linked data may offer several representations of a given resource. Client and server can then agree on the preferred representation via content negotiation, in which the client specifies its preference by using the Accept header in its HTTP request and the server responds in a way that matches the preference the best. Applications can use this practice to request machine-readable representations in RDF, while browsers may ask for human-readable HTML.
Crawling data describing linked data resources is usually done by dedicated tools, such as LDSpider. However, if you manage to simplify the crawling task, LinkedPipes ETL (LP-ETL) can execute it via the HTTP GET list component. This component accepts configuration in RDF that lists the URLs to download.
We demonstrate the use of the HTTP GET list component on harvesting code lists linked from a data structure definition (DSD) described by the Data Cube Vocabulary (DCV). In DSDs, code list of a property enumerates the concepts that are valid objects of the property. Properties link their code lists by the qb:codeList property. Data describing code lists has many uses. For example, you may fetch code lists for validation of the integrity constraint 19 from DCV, which tests whether all objects of a property are members of the code list defined by the property. Code lists can also provide labels that user interfaces for DCV datasets can display instead of the IRIs of code list concepts.
We use the DSD for expenditures in the 2015 budget of Athens, Greece for our example. The DSD can be downloaded by the HTTP GET component and turned into RDF by the Files to RDF single graph component. Alternatively, you may want to get your source of links from a SPARQL endpoint, which you can query via the SPARQL endpoint component.
Configuration for the HTTP GET list component can be generated via a SPARQL CONSTRUCT query executed by the SPARQL CONSTRUCT component. The configuration is described by terms from the http://plugins.linkedpipes.com/ontology/e-httpGetFiles# namespace, thereafter abbreviated by the prefix httpList. The configuration instantiates httpList:Configuration and refers to one or more instances of httpList:Reference via the httpList:reference property. Each reference specifies its URL via the httpList:fileUri property and the name of the file to store the obtained response, declared by the httpList:fileName property. To avoid prohibited characters you can generate the file names as SHA1 hashes of the code lists' IRIs concatenated with the appropriate suffix of the requested RDF serialization, such as .ttl for Turtle. References can optionally link HTTP headers, instances of httpList:Header, via the httpList:header property. Each header is described as a combination of a key (httpList:key) and value (httpList:value). In our example, we use content negotiation and specify the Accept header to ask for RDF in the Turtle or N-Triples syntaxes, followed by anything else. Any response will be attempted to be parsed as Turtle. Parsing N-Triples as Turtle works because N-Triples is a subset of Turtle. Otherwise, if responses that cannot be read as Turtle are downloaded, parsing them will fail and they will be ignored. Let's have a look at the SPARQL CONSTRUCT query that generates the configuration for HTTP GET list from a DSD:
PREFIX : <http://localhost/>
PREFIX httpList: <http://plugins.linkedpipes.com/ontology/e-httpGetFiles#>
PREFIX qb: <http://purl.org/linked-data/cube#>
CONSTRUCT {
:config a httpList:Configuration ;
httpList:reference ?codeList .
?codeList a httpList:Reference ;
httpList:fileUri ?url ;
httpList:fileName ?fileName ;
httpList:header :header .
:header a httpList:Header ;
httpList:key "Accept" ;
httpList:value "text/turtle,application/n-triples;q=0.9,*/*;q=0.8" .
}
WHERE {
{
SELECT DISTINCT ?codeList
WHERE {
[] qb:codeList ?codeList .
}
}
BIND (str(?codeList) AS ?url)
BIND (concat(sha1(str(?codeList)), ".ttl") AS ?fileName)
}
We pipe the RDF generated by this query to HTTP GET list. We leave the Number of threads used for download parameter with the default value of 1. Increasing this parameter allows to download multiple URLs in parallel. However, since we do not want to overload servers with concurrent requests, we request the individual URLs serially. We switch the Force to follow redirects parameter on to allow redirects from HTTP to HTTPS. We also turn on the Skip on error parameter to make the pipeline more fault-resistant. That way, if downloading a URL produces an error, it is simply skipped. To enable better debugging we also switch on the Detailed log option, which makes the component output richer logs that may explain why downloading some URLs fails. We set the Timeout parameter to 30 seconds to cut off long-running requests that may halt the pipeline execution. Overall, the configuration of the component looks like this:
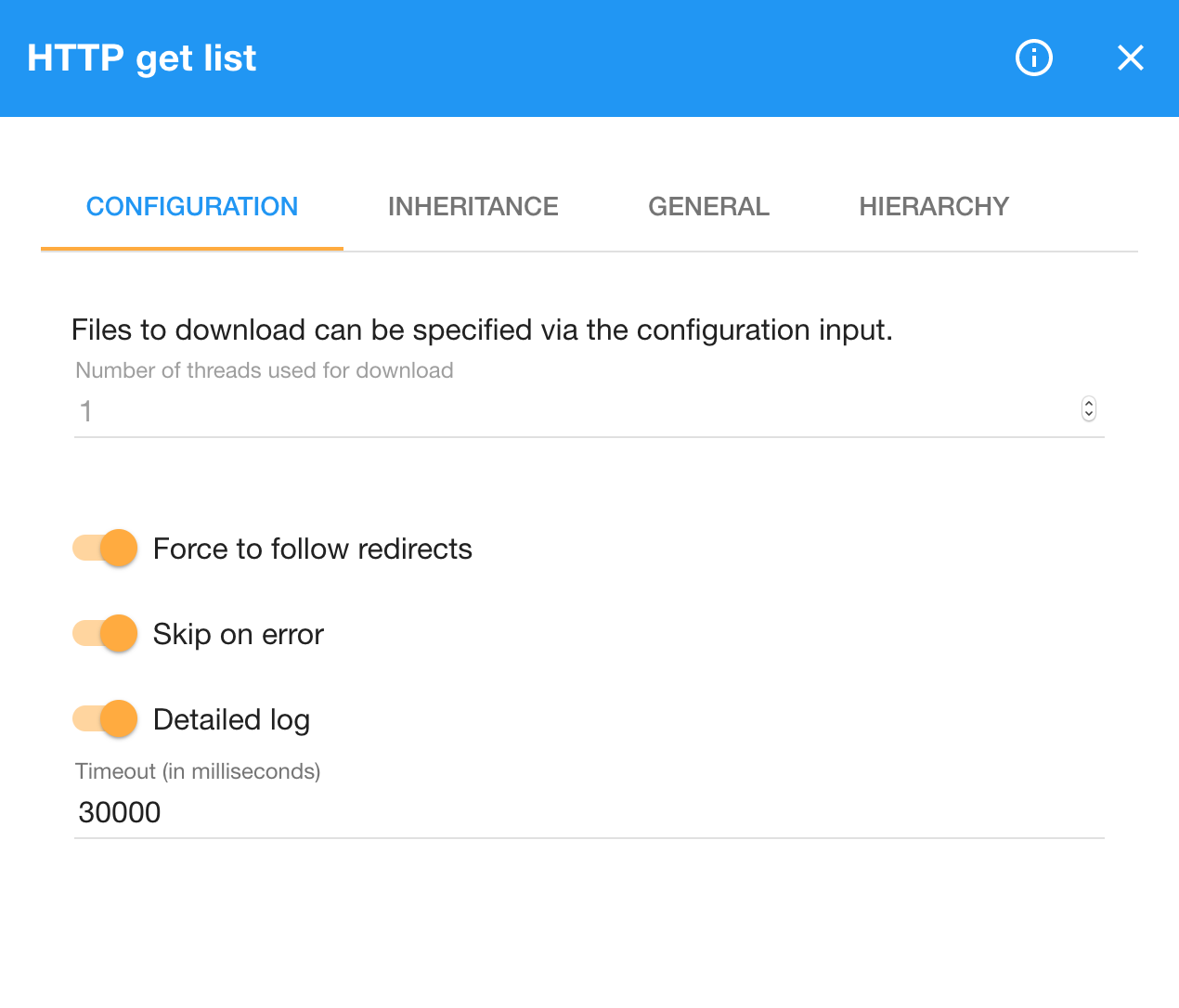
Running the pipeline downloads the code lists referenced from the given DSD. The code lists can be then turned into RDF via the Files to RDF or Files to RDF single graph components. By default, these components will attempt to parse their input as the suffix of its file name implies. We generated file names with the .ttl suffix, so the files are parsed as Turtle. In these components we can switch the Skip file on failure parameter to ignore files that fail to be parsed as Turtle.
Now that we have the data describing the linked code lists, there are several ways how to cache it locally. For instance, we can push it to an RDF store via the Graph store protocol component. In that case there is an opportunity to simplify the pipeline. If you trust that the downloaded data will be valid RDF, you can skip the parsing and reserialization and pipe the output of the HTTP GET list component directly to the Graph store protocol component.
The described pipeline is available here. It has the following structure:
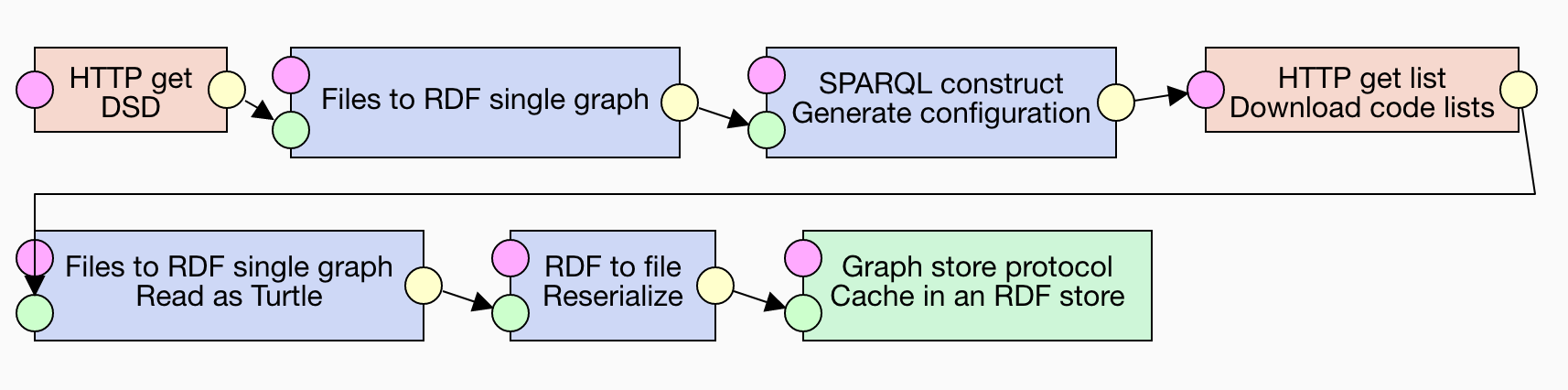
Discussion
We can extend the number of hops that we crawl by piping the crawled data into another instance of the HTTP GET list component. For example, we can first extract a link to a dataset's DSD, download it, and then extract links to code lists from the DSD. That way we can approach the crawling capabilities of the more sophisticated tools for harvesting data from the Web.
See also
As mentioned in the solution, if you require a more fully fledged tool for crawling linked data, you can use LDSpider, for example.