How to load data to Virtuoso
You want to load data to the Virtuoso RDF store, particularly large data from multiple files that belongs into several named graphs.
Problem
Virtuoso, especially its open-source version, is a commonly used RDF store. You can load data to Virtuoso by its bulk loader. This is a Virtuoso-specific solution. However, the standards-based SPARQL 1.1 Graph Store HTTP Protocol does not support loading data in quad-based RDF syntaxes that specify named graphs. Instead, named graph IRIs must be provided by a query parameter. If you want to load multiple files into multiple named graphs, the Virtuoso bulk loader can do it for you. Moreover, it can provide better performance than the Graph Store Protocol. Nevertheless, it is a Virtuoso-specific solution for loading data, so it requires a Virtuoso-specific LinkedPipes ETL (LP-ETL) component.
Solution
Since Virtuoso is so widespread, LP-ETL offers a special component to load data into this RDF store, the Virtuoso loader. It allows you to load data via the afore-mentioned Virtuoso bulk loader. The configuration of this component involves serveral parameters.
In order to connect to a Virtuoso instance you must provide a JDBC connection string, which is jdbc:virtuoso://localhost:1111/charset=UTF-8/ for default Virtuoso installations. To authorize the connection, provide the access credentials of a Virtuoso user allowed to load data. By default, Virtuoso offers a user with the name dba and the password dba.
Files are loaded from a configured directory. Their names must match a given mask. If you want to load one file, specify its name as the mask. Otherwise, if you want to load multiple files, you can match their names by using the asterisk wildcard. For instance, the mask *.ttl matches all files in the Turtle syntax and the mask * matches any file in the directory.
IRI of the named graph into which the data is loaded is determined via the Target graph IRI parameter. When no named graph is given, then the data is loaded into the unnamed default graph, unless the input data references named graphs. If the input is serialized in a quad-based format, such as N-Quads or TriG, then it is loaded into the named graphs that it specifies, overriding the named graph IRI from the component's configuration.
The Clear target graph before loading option allows you to delete any data in the configured target graph prior to loading the given data. This comes in handy when you run a pipeline that contains a Virtuoso loader repeatedly, such as in during its development or when executed periodically to fetch updates in data. The component clears only the named graph given in the configuration. Named graphs specified in the input data are not cleared. As a result, using this option makes sense only when dealing with a single known named graph.
You would typically switch the Clear load list option on, unless you want Virtuoso to keep an audit record of the loaded data in the db.dba.load_list table. You can use multiple CPU threads to load data in parallel by increasing the Number of loaders to use. Finally, the Status update interval in seconds specifies how often the component should poll Virtuoso about the status of the bulk load process. You can leave this option with its default value unless you want to monitor the load process closely.
Virtuoso loader is a peculiar component, since it receives its input indirectly. Unlike other LP-ETL components that receive data via an input edge, it sources data directly from the file system of the server that runs the Virtuoso instance. Consequently, the data to load must be first serialized to RDF files and then copied to the server via the Files to SCP component. In order to ensure that the Virtuoso loader is run only after the Files to SCP component has completed, drag a Run before edge from the Files to SCP to the Virtuoso loader.
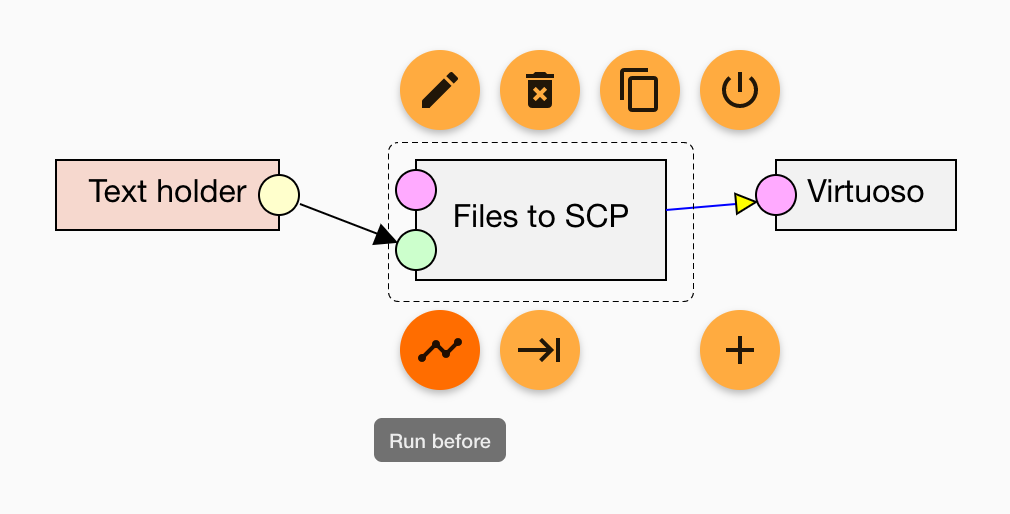
Note that the directory where the files to load are must be included in the values of the DirsAllowed parameter in the virtuoso.ini configuration file. The parameter must include either the directory or its parent directory to allow loading data from it. Remember to restart the Virtuoso instance (e.g., by running service virtuoso-opensource restart) to put the changes in the configuration into effect.
An example pipeline for loading data into Virtuoso can be found here.
Discussion
The Virtuoso bulk loader recognizes several RDF syntaxes based on their file suffixes. Make sure you use the correct suffix so that the loader files can be parsed successfully. The files to load can be either uncompressed or compressed via GZip, as indicated by the additional .gz file name extension. Since RDF serializations tend to be verbose, you can save some time spent transferring the data if you compress it before.
Since the components involved in loading data to Virtuoso require you to provide access credentials, pipelines containing them should be exported without the credentials if you want to share them publicly. Instead of removing the confidential information manually, LP-ETL offers an option to remove it automatically via the Download without credentials action.
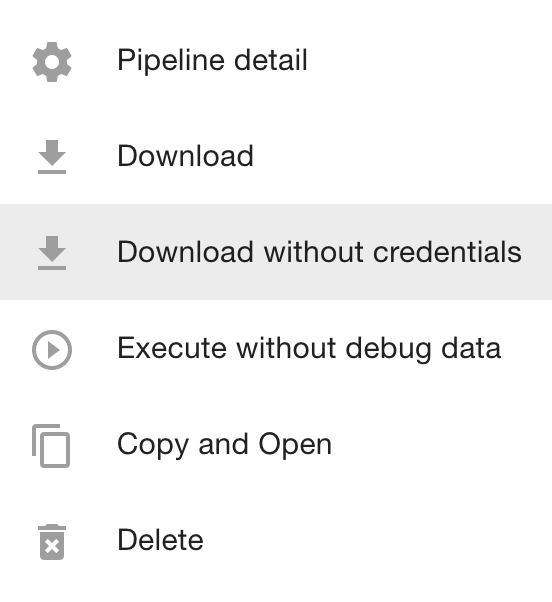
If you remove credentials from components that require them, the components will not work unless the required credentials are provided again. Therefore, it is a good practice to disable these these components in the pipelines exported without credentials. You can either disable individual components or use the mass action Disable loaders to disable all loaders in a pipeline.

See also
You can also load data into Virtuoso by using the Graph store protocol component that operates via the standard SPARQL 1.1 Graph Store HTTP Protocol. You would use this component if you need to load data to RDF stores other than Virtuoso.